この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
検索順位を調べたいだけなのに、Web Scraper APIも出てくる。商品ページの価格を集めたいだけなのに、SERP APIという名前も見かける。ここで迷う人は多いと思います。
先に結論を言うと、SERP APIは検索結果を見るための道具、Web Scraper APIは特定ページの中身を構造化して受け取るための道具です。イメージとしては、SERP APIが「駅前の看板や店の並びを見る係」、Web Scraper APIが「特定のお店に入って値札やレビュー棚を確認する係」です。
たとえばSEO担当者が「自社記事がどの順位にいるか」を週1回見たいなら、まずSERP APIが候補になります。EC担当者が「競合5商品の公開ページから価格、在庫表示、レビュー数をGoogle Sheetsへ残したい」なら、Web Scraper APIの方が考えやすいです。どちらが上という話ではなく、見たい場所が違います。
– SERP APIとWeb Scraper APIの役割の違い
– SEO調査、EC価格調査、AIリサーチでの選び方
– 初心者が最初に小さく試す順番
– n8n、Google Sheets、BI、AIメモへ広げる考え方
– 公開Webデータを安全に扱うための境界線
まず違いは「検索結果を見るか、ページ中身を見るか」
SERP APIのSERPは、検索結果ページのことです。GoogleやBingなどで検索したときに出てくる順位、タイトル、URL、広告、ローカル枠、ショッピング枠などを、扱いやすい形で受け取るための入口です。公式ドキュメントでも、SEO順位チェック、キーワード監視、AIエージェントの検索材料、ブランド保護、競合調査などの用途が案内されています。
一方、Web Scraper APIは、特定サイトや特定ページから必要なデータを取り出して、JSONなどの形で受け取るための入口です。Bright Dataの公式情報では、Web Scraper APIは準備済みのスクレイパーを使い、同期処理と非同期処理を用途に分けて使える仕組みとして説明されています。短く言うと、検索画面ではなく、ページの中身を見る道具です。
身近なたとえで言えば、SERP APIは商店街の地図を見る作業です。どのお店が目立つ位置にあるか、広告看板がどこに出ているかを見ます。Web Scraper APIは、気になるお店に入って、棚の値札、在庫札、レビューカードをメモする作業です。ここを分けると、選び方がかなり楽になります。

SERP APIが向いているのは検索結果の定点観測
SERP APIが向いているのは、「検索したときに何が出ているか」を同じ条件で見たい場面です。SEO担当者なら、狙っているキーワードで自社記事が何位か、上位にどんなタイトルが多いか、広告が出ているかを確認します。
これは、駅前の掲示板を毎週同じ時間に写真で残すようなものです。1回見るだけなら手作業でも十分です。ただ、キーワードが20個になり、地域や言語の条件もそろえたいとなると、人のメモだけではズレやすくなります。SERP APIなら、検索エンジン、国、言語、取得形式をそろえ、順位、タイトル、URLなどを表に残しやすくなります。
実務例としては、ブログ運営者が毎週月曜に「AIライティングツール 比較」「SEO 自動化」「Webデータ 収集」など5キーワードを確認し、順位、タイトル、URL、広告の有無をGoogle Sheetsに入れる形です。AIに渡す場合も、いきなり「市場を調べて」と頼むより、検索結果の材料をそろえてから「上位に多い切り口を整理して」と頼む方が見直しやすいです。
注意点もあります。検索順位は、正しさの保証ではありません。上位にあるから正しい、広告に出ているから良い、という判断は危ないです。元ページ、公開日、公式情報かどうかを人が最後に確認します。
Web Scraper APIが向いているのはページ内データの整理
Web Scraper APIが向いているのは、特定の公開ページから決まった項目を取り出したい場面です。たとえばECの商品ページなら、価格、在庫表示、レビュー数、商品名、キャンペーン文言。レビューページなら、評価、件数、投稿日、見出し。ニュースページなら、タイトル、公開日、URLです。
イメージとしては、店頭の棚卸しに近いです。検索結果で「どの店が目立つか」を見るのではなく、実際に棚を見て、値札や在庫札を同じ表に写します。Bright DataのWeb Scraper APIは、こうしたページごとの情報を構造化して受け取るための候補になります。
初心者が最初に試すなら、対象は5URLくらいで十分です。EC担当者が競合5商品の公開ページを週1回見て、価格、在庫表示、レビュー数、キャンペーン文言、取得日をGoogle Sheetsに残す。このくらいなら、何を見たいかがはっきりします。ここでつまずきやすいのは、「取れるものを全部取ろう」とすることです。最初は、仕事の判断に使う列だけで十分です。
ただし、Web Scraper APIも万能ではありません。サイト構造が変われば確認が必要ですし、非公開ページやログイン後の画面を対象にしてよいわけではありません。公開情報だけ、必要な項目だけ、小さな頻度から始めます。
最初の選び方は目的から逆算するといい
どちらを選ぶかは、機能名から考えるより、作業から考える方が早いです。検索結果の並び、順位、広告、ローカル表示を見たいならSERP API。特定ページの価格、レビュー、在庫表示、記事タイトルを取りたいならWeb Scraper API。まずはここまで分かれば十分です。
たとえば「自社記事の検索順位が落ちたか知りたい」なら、SERP APIです。見たいのは検索結果の並びだからです。「競合商品の価格が変わったか知りたい」なら、Web Scraper APIです。見たいのは商品ページの中身だからです。
料理でたとえると、SERP APIは献立表を見て人気メニューを把握する作業、Web Scraper APIは実際の料理の材料や値段をメモする作業です。献立表だけでは材料は分かりません。材料表だけでは、店頭でどれが目立っているかは分かりません。両方が必要な仕事もあります。
普通の仕事ではこう使い分ける
1つ目は、SEO記事の順位チェックです。ブログ運営者が毎週月曜に5キーワードをSERP APIで確認し、順位、タイトル、URL、広告の有無、取得日をGoogle Sheetsに残します。前週より大きく下がった記事だけ、タイトルや導入文、内部リンクを見直します。これは、毎週同じ棚の位置を写真で残して、置き場所が変わった商品だけ見るような作業です。注意点は、順位だけで記事の良し悪しを決めないことです。
2つ目は、EC価格と在庫表示の確認です。EC担当者が競合5商品の公開ページをWeb Scraper APIで確認し、価格、在庫表示、レビュー数、セール文言、取得日を表に残します。前週との差分が出た商品だけ、人がページを開いて確認します。スーパーの値札を毎週同じ列でメモするイメージです。注意点は、対象サイトのルールを確認し、頻度を上げすぎないことです。
3つ目は、広告運用やブランド調査です。広告担当者が自社名、商品名、カテゴリ名で検索結果を見て、どんな広告文や比較記事が出ているかをSERP APIで残します。そのうえで、気になる比較ページや公開レビューだけWeb Scraper APIで詳しく見ます。駅前の看板で目立つ店を見つけて、必要な店だけ中に入って確認する流れです。注意点は、広告文やレビューをそのままコピーせず、傾向を見る材料にすることです。
4つ目は、AIリサーチの材料作りです。AIリサーチ担当者がSERP APIで上位URLを集め、Web Scraper APIで公開ページのタイトル、日付、要点の候補を整理し、AIメモに渡します。AIには「この材料から今週見るべき変化を3つに整理して」と頼みます。学校のレポートで参考文献リストを先に作るのと同じです。注意点は、AIの要約をそのまま信じず、元URLへ戻って人が確認することです。
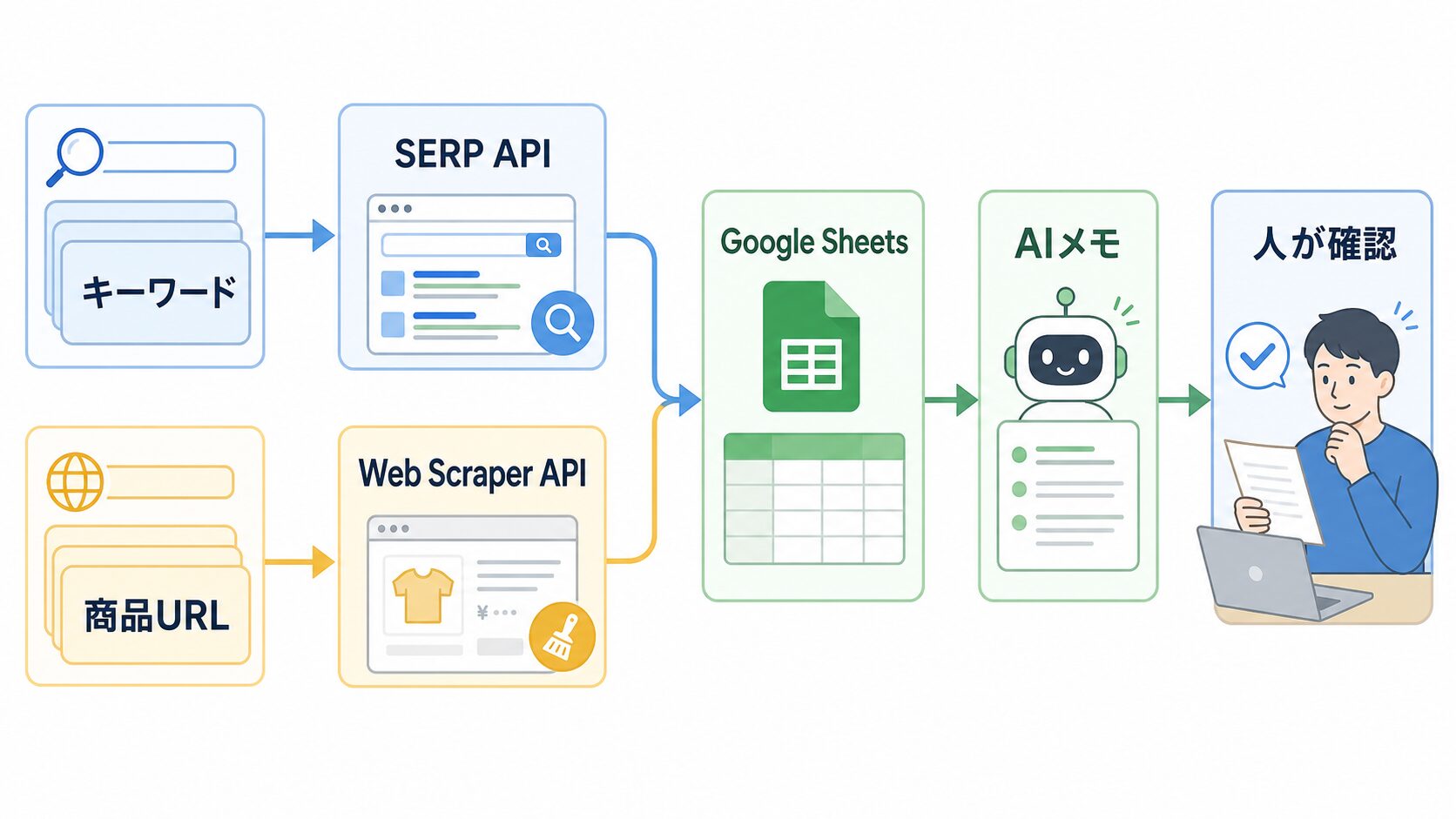
慣れてきたらn8nやBIへ広げられる
基本の流れが動いたら、n8n、Google Sheets、BIダッシュボード、AIリサーチノートへ広げられます。ここがポイントです。APIを使う価値は「取ること」だけではなく、同じ条件で残り、人が見返せることにあります。
たとえばn8nで毎週月曜にワークフローを動かし、キーワード一覧はSERP APIへ、商品URL一覧はWeb Scraper APIへ送ります。結果はGoogle Sheetsに追記します。前週との差分だけAIメモに送り、「順位が下がったキーワード」「価格が変わった商品」「新しく出てきた広告文」を短く整理します。
BIへ広げるなら、月次で見る項目を絞ります。キーワードごとの順位推移、競合商品の価格帯、在庫切れ表示の回数、広告表示の増減などです。ダッシュボードは豪華に作る必要はありません。最初は、変化があった行だけ色が付くくらいで十分です。
ただ、最初から全部つなぐ必要はありません。まずは1テーマ、5キーワード、5URL、週1回。ここで列の形が固まってからn8nやBIに広げる方が、後で直す手間が少なくなります。
逆に、これはやらない方がいいです
逆に、これはやらない方がいいです。検索結果やページ情報を大量に取って、そのままAI記事や広告判断へ流し込むことです。データは材料であって、結論ではありません。検索結果には広告、古いページ、比較記事、公式情報、個人の感想が混ざります。ページ内データも、取得日や対象条件を残さないと、あとで意味が分からなくなります。
もう1つ避けたいのは、公開情報の範囲を超える使い方です。Bright DataのAcceptable Use Policyでも、非公開情報の収集、スパム、広告不正、偽アカウント作成などは禁じられています。ログイン後の画面、個人情報の無断収集、サイトのルールに反する使い方、迷惑な高頻度アクセスは避けてください。
たとえるなら、公開されている店頭価格をメモするのと、店の裏側の帳簿を見ようとするのはまったく別です。Bright Dataを使う場合も、公開Webデータ、規約確認、少量テスト、人の確認。この4つを先に決めておくと安全に進めやすいです。
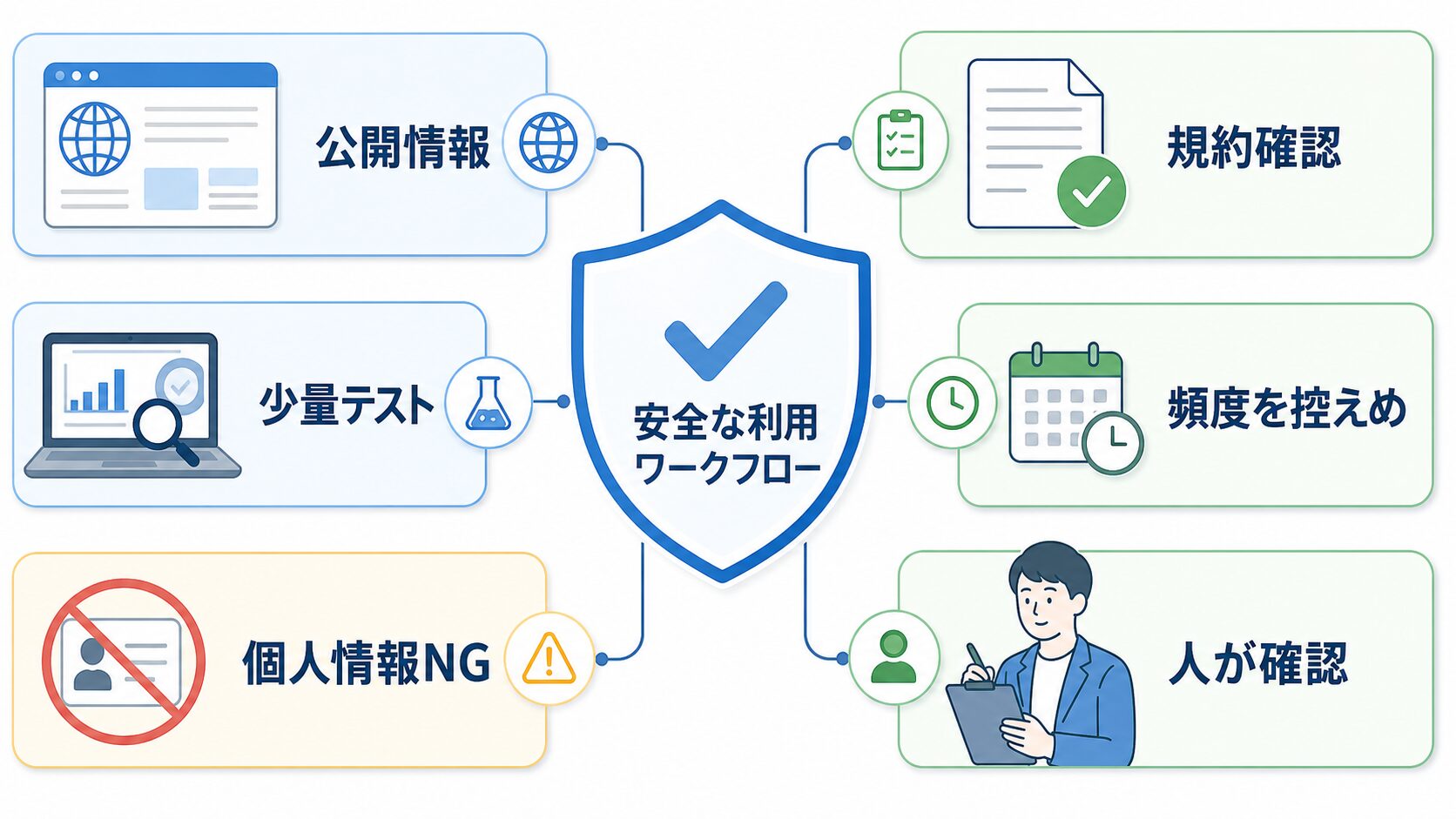
対象は公開Webデータに絞ります。サイト規約、robotsの考え方、プライバシー、適用される法律を確認し、少量から試してください。非公開情報、個人情報の不適切な保存、スパム、アカウント悪用、不正アクセスには使わないでください。
Bright Dataが合う人、まだ早い人
Bright Dataが合うのは、検索結果や公開ページを継続して仕事の判断材料にしたい人です。SEO担当者、EC運営者、広告運用者、メディア運営者、AIリサーチ担当者のように、毎週または毎月同じ項目を見る人には向いています。
反対に、月に1回だけ数ページを見る人なら、最初は手作業や普通のスプレッドシートで十分です。道具を入れる前に、どの項目を、どの頻度で、どこに残し、何の判断に使うのかを決める方が先です。これは、家計簿アプリを入れる前に「何費を見たいのか」を決めるのと同じです。
SERP APIとWeb Scraper APIを両方使う場合もあります。検索結果で候補ページを見つけ、必要な公開ページだけ中身を整理する流れです。ただし、最初から両方を一気に入れる必要はありません。まずは自分の作業が「検索結果を見る仕事」なのか「ページ中身を見る仕事」なのかを分けてください。
まとめ
SERP APIとWeb Scraper APIの違いは、難しく考えすぎなくて大丈夫です。SERP APIは検索結果を見るための道具。Web Scraper APIは特定ページの中身を構造化して受け取るための道具です。
SEO順位、広告表示、上位URL、地域別の検索結果を見たいならSERP API。商品ページの価格、在庫表示、レビュー数、ニュース記事の公開日などを表にしたいならWeb Scraper API。慣れてきたら、n8n、Google Sheets、BI、AIメモへつなげると、毎週の確認作業を見直しやすくできます。
最初は小さくて十分です。5キーワードか5URLを週1回だけ。公開情報に絞り、規約を確認し、取得日と元URLを残し、人が最後に見る。この順番なら、初心者でもBright Dataの使い分けを無理なく始められます。