

この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
サイトを見直したいとき、1ページずつ開いてタイトル、本文、URL、更新日をメモしていく作業は、思った以上にしんどいです。10ページならまだできます。でも、100ページ、500ページ、競合サイトも含めて毎月見るとなると、だんだん抜けます。どこまで見たかも分からなくなります。
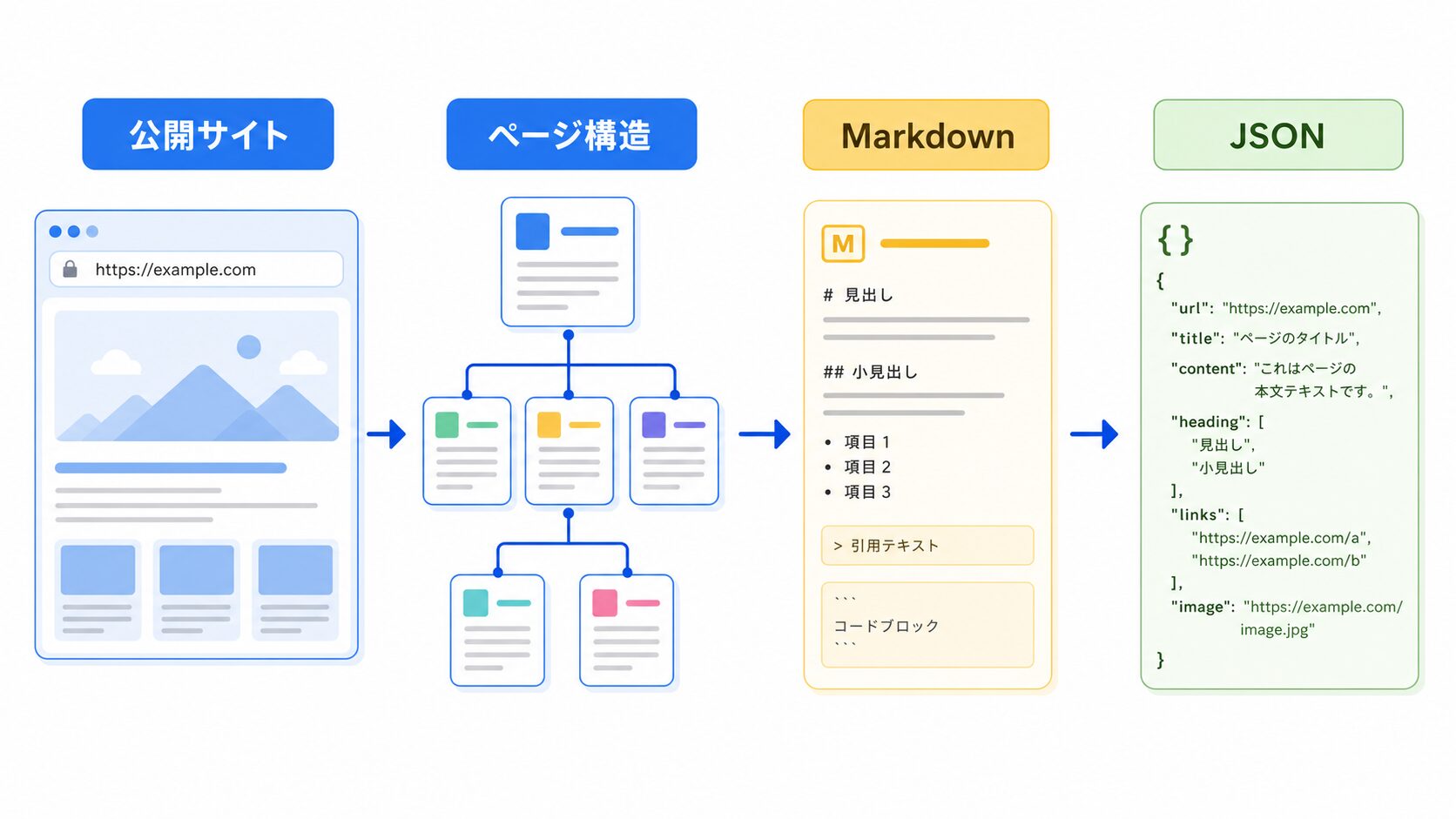
Bright Data Crawl APIは、ざっくり言うと、**公開されているWebサイト全体をたどり、ページ内容をMarkdown、HTML、JSONなどの形で整理しやすくするための機能**です。イメージとしては、図書館の本棚を1冊ずつ読むのではなく、まず棚の場所、タイトル、章立て、メモしやすい形を一覧にする係を置く感じです。
この記事では、サイト全体の情報整理をしたい初心者向けに、Crawl APIで何ができるのか、普通の仕事ではどう使えるのか、慣れてきたらSheets、BI、AIリサーチメモへどう広げられるのかを整理します。最初に言っておくと、これは「どんなサイトでも好きに丸ごと取ってよい」という話ではありません。公開情報だけを、サイトのルールや法律を確認しながら、小さく試すのが前提です。
– Bright Data Crawl APIの基本的な役割
– Web Scraper APIや手作業との違い
– SEO監査、サイト移行、競合調査での使い道
– Sheets、BI、AIメモへ広げる考え方
– 公開Webデータを扱うときの安全な境界線
Crawl APIは「サイト全体の棚卸し」をする入口
Crawl APIの役割を一言でいうと、公開サイトの中をたどって、ページ構造や本文を仕事で使いやすい形に整理することです。Bright Dataの公式ドキュメントでも、Crawl APIはドメイン全体をマップし、Markdown、HTML、JSONとして内容を抽出する機能として案内されています。難しく聞こえますが、最初は「Webサイトの棚卸し係」と考えると分かりやすいです。
身近なたとえなら、引っ越し前の部屋チェックです。いきなり段ボールへ詰めるのではなく、まず本棚、机、押し入れ、キッチンに何があるかを見ます。Webサイトでも同じです。どのURLがあり、どんな見出しがあり、本文がどれくらいあり、どのページが古そうか。先に全体を見ないと、どこから直すべきか判断しにくいです。
ここでつまずきやすいのは、Crawl APIを「単にたくさんページを取る道具」と見てしまうことです。大事なのは量ではありません。たとえば、メディア運営者が自分のサイトの公開記事を月1回確認し、URL、タイトル、見出し、更新日、カテゴリ、内部リンクの有無を一覧にする。そこから「古い記事を直す」「重複したテーマをまとめる」「AIメモへ渡して改善候補を出す」といった判断に進みます。
最初はここまで分かれば十分です。Crawl APIは、サイトを一気に魔法のように改善する機能ではなく、**サイト全体を見える状態にして、人が判断しやすくするための入口**です。
Web Scraper APIとの違いは、見る範囲です
Bright DataにはWeb Scraper APIもあります。これとCrawl APIの違いで迷う人は多いです。初心者向けに分けるなら、Web Scraper APIは「決めたページから決めた項目を取る」、Crawl APIは「サイト全体の構造や内容をまとめて見る」という違いです。
たとえば、競合10商品の公開ページから価格、在庫表示、レビュー数を週1回取りたいなら、Web Scraper APIの方が考えやすいです。見るURLも、欲しい項目もかなりはっきりしています。一方で、競合サイト全体のカテゴリ構成、記事タイトル、公開ページの一覧、古いキャンペーンページの残り方を見たいなら、Crawl APIの考え方が合います。
イメージとしては、Web Scraper APIが「棚の中の特定商品だけ値札を見る係」、Crawl APIが「店全体の棚割りを見て、どの棚に何があるかを記録する係」です。どちらが上ではありません。見たい範囲が違います。
実務では、サイトリニューアル前の棚卸しが分かりやすいです。担当者が自社サイトの公開ページを確認し、URL、タイトル、見出し、本文量、更新日、カテゴリを整理します。結果はGoogle Sheetsへ入れ、移行対象、削除候補、リライト候補を分けます。ここで迷いやすいのは、本文を全部AIに渡せばすぐ答えが出ると思ってしまうことです。実際には、最初に列を絞る方が扱いやすいです。
URL、タイトル、H1/H2、カテゴリ、更新日、本文の有無、内部リンク、取得日くらいから始めると、あとで判断に使いやすくなります。
まずは「自分の公開サイトを20ページ」からで十分です
Crawl APIを試すなら、最初から大きく始めない方がいいです。おすすめは、自分の公開サイトや管理しているメディアから20ページだけ見ることです。見る項目は、URL、ページタイトル、主な見出し、本文のざっくりした有無、更新日、カテゴリ、取得日。これだけでも、かなり発見があります。
料理でいえば、いきなり店の全メニューを作り直すのではなく、まず人気メニュー20品の材料表を確認する感じです。古い材料が混じっていないか、似た料理が重複していないか、説明が足りない料理がないかを見る。Webサイトも同じで、全体を広げすぎると、どこから直せばよいか分からなくなります。
たとえば、ブログ運営者が月初に20記事だけ確認します。Google SheetsにURL、タイトル、見出し、最終更新日、内部リンクの有無、改善メモを残します。古い記事が5本見つかったら、そのうち検索流入がある2本だけ先に直す。地味ですが、こういう順番の方が現実的です。全部を一度に直そうとすると、だいたい止まります。
ここでありがちな失敗は、取れる情報を全部取ろうとすることです。本文全文、画像、リンク、構造化データ、パンくず、全メタ情報まで一気に入れると、表が重くなります。最初は少し物足りないくらいで十分です。仕事で見ない列は、あとで邪魔になります。
普通の仕事ではこう使えます
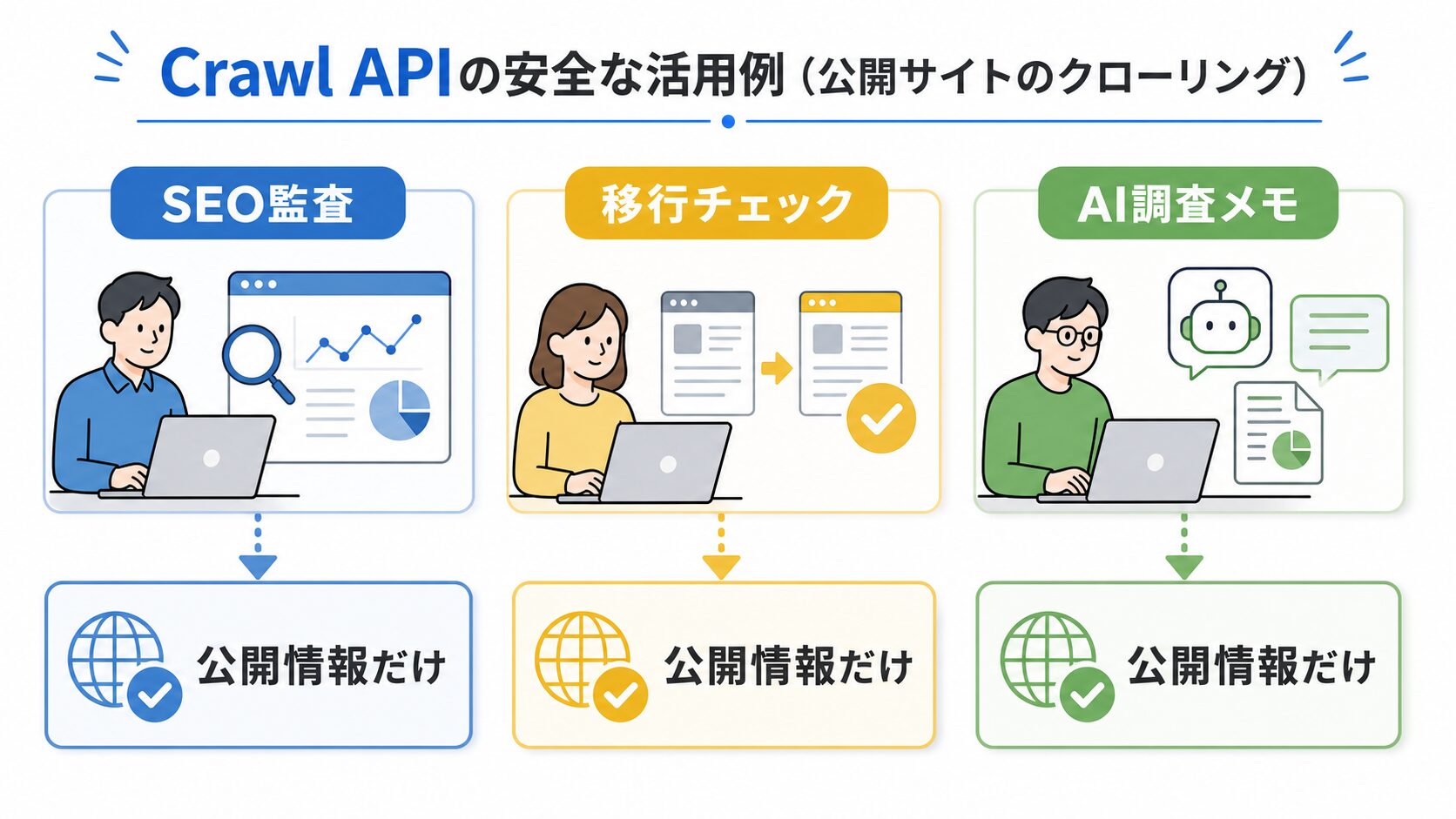
1つ目は、SEO監査です。SEO担当者が自社メディアの公開記事を月1回確認し、URL、タイトル、H1、主なH2、更新日、カテゴリ、内部リンクの有無をSheetsに残します。そこから、古い記事、重複した記事、リンクが少ない記事を見つけます。注意点は、Crawl結果だけで記事の良し悪しを決めないことです。検索意図や実際のページ内容は、人が確認します。
2つ目は、サイト移行チェックです。制作担当者が旧サイトの公開ページをCrawl APIで整理し、移行前のURL一覧、タイトル、主要見出し、画像の有無、移行先URL候補を表にします。これは、引っ越し前に荷物リストを作る作業に近いです。結果はGoogle Sheetsへ置き、移行済み、未移行、削除候補を分けます。ここでつまずきやすいのは、古いページを全部残そうとすることです。残す理由がないページは、リダイレクトや統合も含めて人が判断します。
3つ目は、競合サイトの公開コンテンツ確認です。マーケティング担当者が、競合の公開ブログやキャンペーンページを月1回だけ見て、タイトル、カテゴリ、公開日らしき情報、URL、見出しを整理します。目的は文章をまねることではありません。どのテーマが増えているか、自社サイトに説明不足のテーマがないかを見つける材料にします。店頭の棚を見て「このカテゴリの商品が増えているな」と気づく感覚です。
4つ目は、AIリサーチメモの材料作りです。メディア運営者が、自社の公開記事や公式発表ページをMarkdown形式で整理し、AIメモに「古い情報が混ざっていないか」「似た説明が重複していないか」「内部リンクを足せそうな記事はどれか」を聞きます。ここがポイントです。AIに渡す前に、元URLと取得日を残しておきます。AIの要約だけで判断すると、あとで確認先が分からなくなります。
どの例でも、先に「何を判断するために見るのか」を決めます。削除候補を探すのか、リライト候補を探すのか、競合テーマの増減を見るのか。目的がないままサイト全体を集めても、きれいなデータ置き場が増えるだけです。
慣れてきたらSheets、BI、AIメモへ広げる
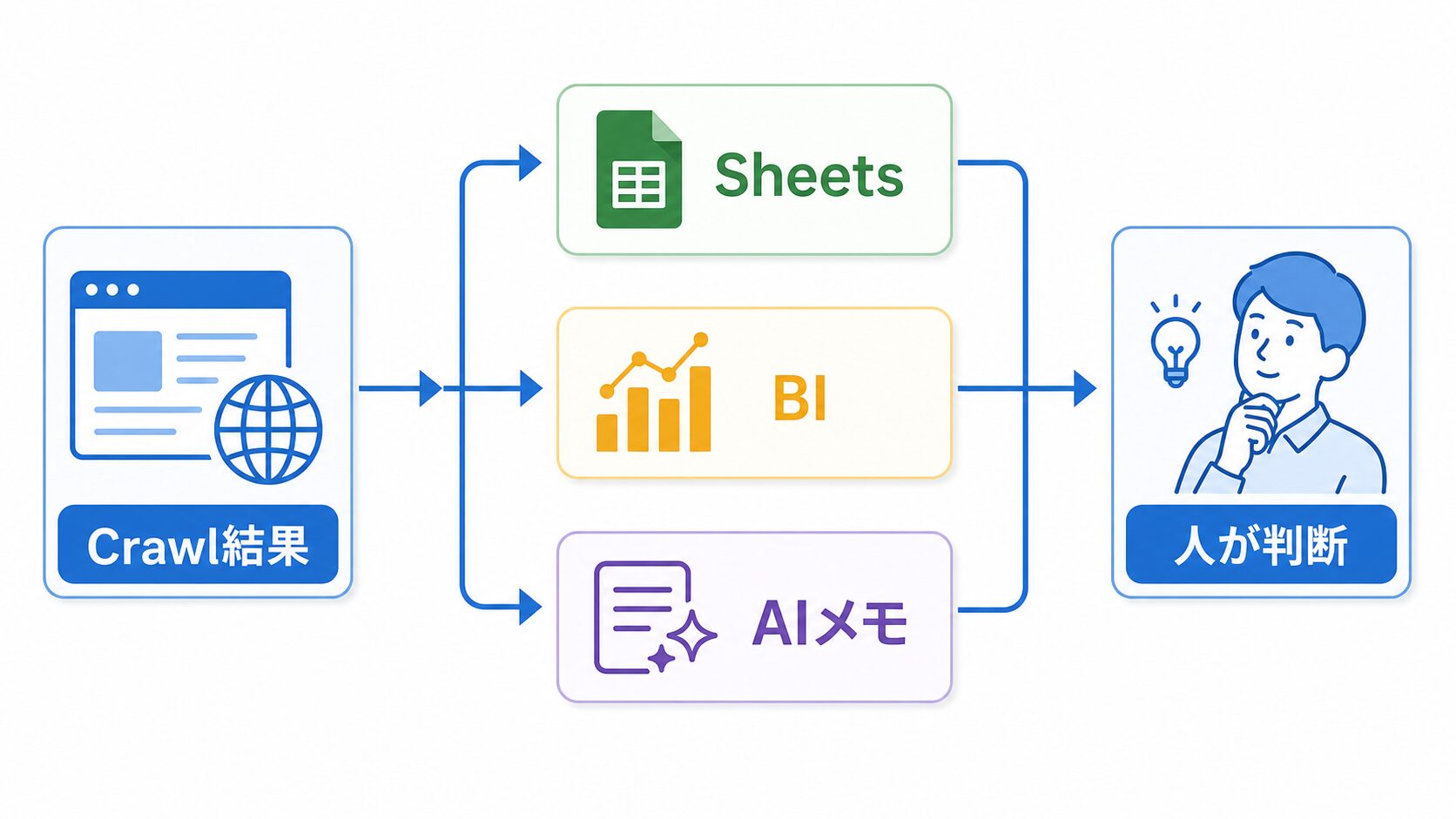
基本の棚卸しが動いたら、次は保存先と見返し方を決めます。Bright Dataの公式情報では、Crawl APIはAPIベースの収集だけでなく、Control Panelからのノーコード操作、Webhookや外部ストレージへの配信、直接ダウンロードにも触れられています。初心者なら、いきなり全部つなぐ必要はありません。最初はCSVやSheetsで十分です。
たとえば、毎月1日に自社サイトの公開記事を確認し、URL、タイトル、主な見出し、更新日、カテゴリ、取得日をSheetsへ残します。次にBIでカテゴリ別の記事数や古い記事数を見ます。さらにAIメモへ「今月リライト候補にする記事」「統合した方がよい近いテーマ」「内部リンクを足せそうな記事」を出してもらう。ここまで来ると、単なる一覧表ではなく、サイト運営の定例チェックになります。
ただし、最初から毎日回す必要はありません。公開サイトの棚卸しなら、月1回やリニューアル前後だけでも価値があります。ここで無理に頻度を上げると、サイトに余計な負荷をかけたり、自分の確認作業が追いつかなかったりします。自動化は便利ですが、見る人がいないデータを増やしても意味が薄いです。
応用例としては、n8nで月初に実行し、結果をGoogle Sheetsへ追記し、前月との差分が大きいページだけAIメモへ送る流れがあります。たとえば、タイトルが変わったページ、本文がほとんど空のページ、古いキャンペーンページ、リンク切れが疑わしいページを人に知らせる。ここまでできると、サイト管理の抜け漏れに気づきやすくなります。
安全に使うための境界線
Crawl APIは公開Webデータを扱うための機能です。だからこそ、境界線を先に決めておく必要があります。使う対象は公開ページに絞り、サイトの利用規約、robotsの考え方、プライバシー、適用される法律を確認します。ログイン後のページ、個人情報、会員限定データ、相手に負荷をかける頻度の取得には近づかない方が安全です。
身近なたとえなら、店頭に並んでいる商品棚を見るのは問題になりにくいですが、店のバックヤードに入って在庫表を見るのは別の話です。Webでも同じです。公開ページのタイトルや見出しを見ることと、非公開情報へアクセスしようとすることはまったく違います。
ログインが必要な情報、個人情報、相手サイトへ過度な負荷をかける取得、スパムやアカウント悪用につながる使い方には使わないでください。最初は小さい範囲、控えめな頻度、公開情報だけで試すのが安全です。
もう1つ大事なのは、Crawl結果をそのまま正解にしないことです。サイトによっては、古いページ、重複ページ、リダイレクト、動的に出る内容があります。エラーも出ます。公式APIリファレンスでも、収集ジョブではsnapshot_idを受け取り、結果を後で取り出す流れが案内されています。つまり、取って終わりではなく、結果を確認して使う前提です。
Crawl APIが向いている人、向いていない人
Crawl APIが向いているのは、サイト全体の公開情報を整理したい人です。SEO担当者、サイト移行担当者、メディア運営者、AIリサーチ担当者、競合コンテンツの変化を見たいマーケティング担当者には合いやすいです。特に、URL一覧を手で作る作業が増えている人には分かりやすいと思います。
一方で、数ページだけ価格を見たい人、特定商品のレビュー数だけを週1回取りたい人、まだ取得したい項目がまったく決まっていない人には、Crawl APIから入ると大きすぎるかもしれません。その場合は、Web Scraper API、Datasets、または手作業の小さな表から始めた方が見通しがよいです。
つまり、Crawl APIは「ページ単位の小さな確認」よりも、「サイト全体を見て、あとで判断しやすくする」場面に向いています。最初は自分の公開サイトを20ページだけ棚卸しする。その結果を見て、リライト候補、移行漏れ、AIメモへの材料を整理する。ここから始めるのが、いちばん現実的です。
まとめ
Bright Data Crawl APIは、公開サイト全体のページ構造や本文を、Markdown、HTML、JSONなどの形で整理しやすくする機能です。初心者は「サイト全体の棚卸し係」と考えると分かりやすいです。
最初にやることは大きな自動化ではありません。自分の公開サイトから20ページだけ選び、URL、タイトル、見出し、更新日、カテゴリ、取得日を表にする。そこから、古い記事、移行漏れ、リライト候補、AIメモへ渡す材料を見つけます。
慣れてきたら、Sheets、BI、n8n、AIリサーチノートへ広げられます。ただし、公開情報だけ、控えめな頻度、サイトルールと法律の確認、人の最終判断。この4つは外さない方がいいです。Crawl APIは、サイトを勝手に良くする魔法ではなく、サイト全体を見える状態にするための道具です。そこが分かると、かなり使いどころが見えてきます。

