この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
Bright Data MCPでAIエージェントに公開Webデータを渡す考え方
AIエージェントに調査を頼んだのに、返ってきた内容が古かったり、元情報を確認しにくかったりして困ることがあります。文章を作るだけならAIは便利ですが、仕事で使う調査では「どの公開ページを見たのか」「いつの情報なのか」「人が確認できるURLが残っているか」が大事になります。
結論から言うと、Bright Data MCPは、AIエージェントに公開Webデータを渡すための入口として考えると分かりやすいです。AIが勝手に何でも判断する仕組みではなく、検索、ページ取得、整理済みデータの確認などを、決まった接続口から扱いやすくするための土台です。
イメージとしては、新人アシスタントに「この棚の資料だけ見て、出典付きでメモして」と頼む感じです。棚に入れてよい資料を決めるのは人間側ですし、最後にメモを読んで判断するのも人間側です。最初はここまで分かれば十分です。
この記事でわかること
- Bright Data MCPとAIエージェントの関係
- 初心者がまず試しやすい公開Webデータの渡し方
- 市場調査、価格チェック、記事下調べでの実務例
- n8n、Googleスプレッドシート、AIリサーチメモへ広げる考え方
- やらない方がいい使い方と安全な境界線
Bright Data MCPとは何か
MCPは、AIと外部ツールをつなぐための共通の接続口です。Bright Data MCPは、その接続口を使って、AIエージェントやAIツールから公開Webデータへアクセスしやすくする仕組みです。
たとえるなら、AI専用の受付カウンターです。AIが「検索したい」「公開ページを読みたい」「ECの商品情報を確認したい」と言っても、毎回バラバラの方法で外に出ていくと管理しにくくなります。MCPという受付を通すことで、どの道具を使うか、どの範囲で調べるかを整理しやすくなります。
Bright Dataの公式情報では、MCP ServerはHosted版とLocal版の両方が案内されています。Hosted版はクラウド上で動く管理済みの入口、Local版は自分の環境側で動かす入口、という理解で大丈夫です。さらに、検索、MarkdownやHTMLでのページ取得、ブラウザ操作系のツール、Amazonなどの構造化データ取得のような機能が用意されています。
ここでつまずきやすいのは、「MCPを入れたらAIが何でも正しく調査してくれる」と考えてしまうことです。MCPは入口であって、判断そのものではありません。実務では、対象URL、調査目的、出力形式、確認担当を決めてから使う方が安定します。
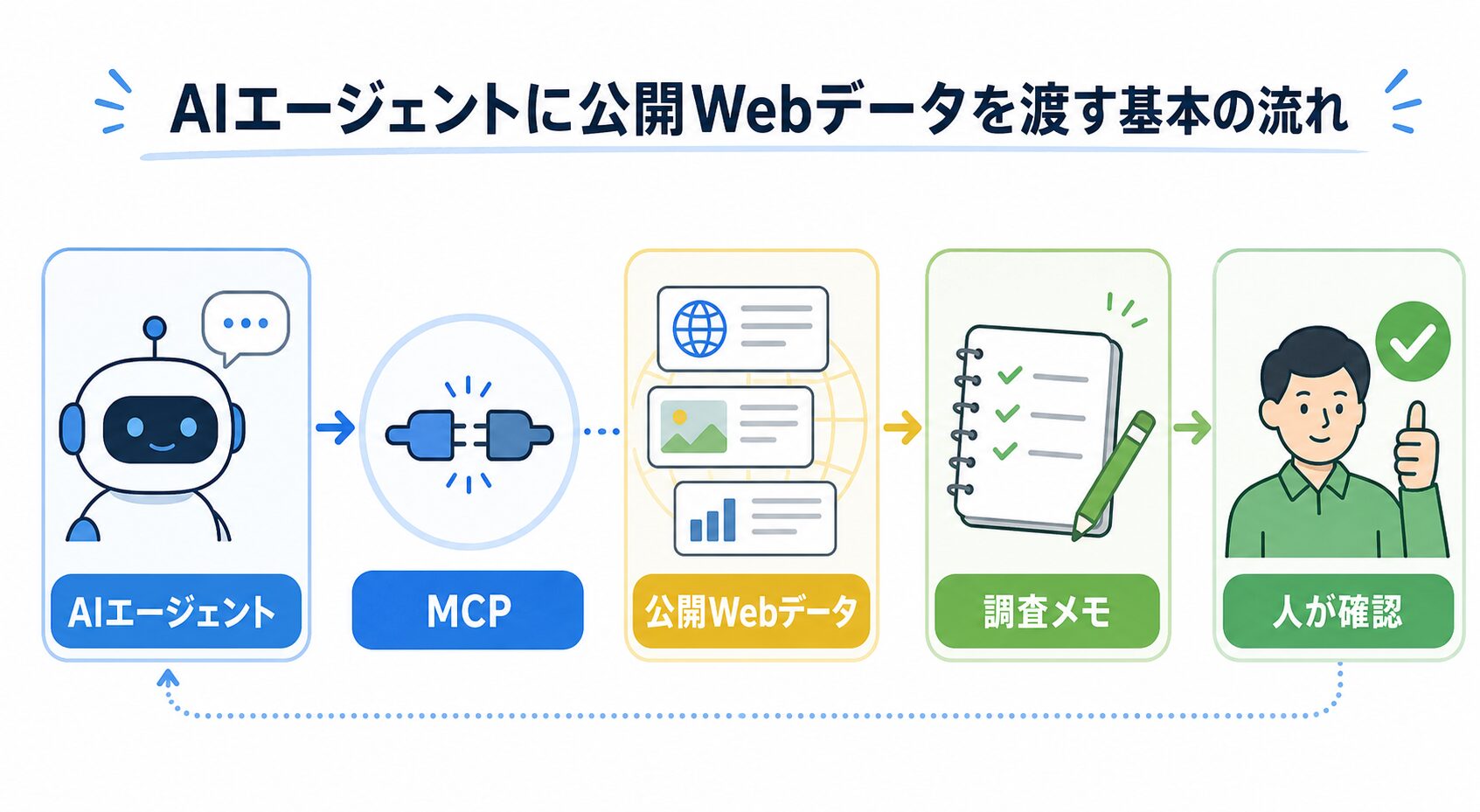
まず何ができるのか
初心者が最初に試すなら、AIエージェントに小さな調査材料を渡すところから始めるのが現実的です。たとえば、特定の商品カテゴリについて公開ページを数件確認し、価格、在庫表示、キャンペーン文言、元URLをメモにまとめるような使い方です。
これは、いきなり大きな調査会社を作るというより、いつも手で開いていたページを「同じ手順で見に行く係」を作る感覚です。AIエージェントには、集めた材料を読みやすく並べてもらいます。人間は、元URLを開いて確認し、仕事で使ってよい情報かどうかを見ます。
実務の小さな例で言うと、ブログ運営者なら「今週のAIツール関連ニュースを5件だけ集めて、記事ネタになりそうな疑問を3つ出す」といった使い方が考えられます。EC担当者なら「競合商品の公開価格と在庫ラベルを週1回確認して、変化があった商品だけ表に残す」という形です。
最初は1テーマ、5から10URL、週1回くらいで十分です。いきなり大量に集めるより、元URLと取得日が残る小さな流れを作る方が続きます。
普通の仕事ではどう使うのか
1つ目の使い道は、市場調査です。たとえば、新しいAIサービス、価格改定、業界ニュース、競合の導入事例など、公開されている情報を少数だけ定点観測します。AIエージェントには、見出し、発信元、公開日、気になるキーワードを整理してもらいます。これは、毎週同じ棚を見て、新しく増えた資料だけ付箋で残すような作業です。
2つ目は、ECの価格チェックです。公開されている商品ページを対象に、価格、在庫表示、セール文言、レビュー件数のような項目を確認します。結果はGoogleスプレッドシートに並べると見返しやすくなります。ただし、価格だけを見て自動で意思決定するのではなく、送料、販売条件、キャンペーン期間など、人が読むべき背景も残します。
3つ目は、記事やSEOの下調べです。検索結果、公式ヘルプ、競合記事、ニュースリリースなどの公開情報を集め、記事構成の材料にします。AIエージェントには「共通して出てくる疑問」「初心者がつまずきそうな言葉」「一次情報として見直すべきURL」を出してもらうと便利です。つまり、AIに完成記事を丸投げするのではなく、机の上に参考資料を並べてもらうイメージです。
4つ目は、ブランドや評判の観測です。自社名、商品名、サービス名で検索し、検索結果や公開レビューの変化を見ます。ここで大事なのは、個人を追いかけることではなく、公開されている話題の傾向をざっくりつかむことです。元URLと日時を残しておくと、あとで「なぜその判断をしたのか」を説明しやすくなります。
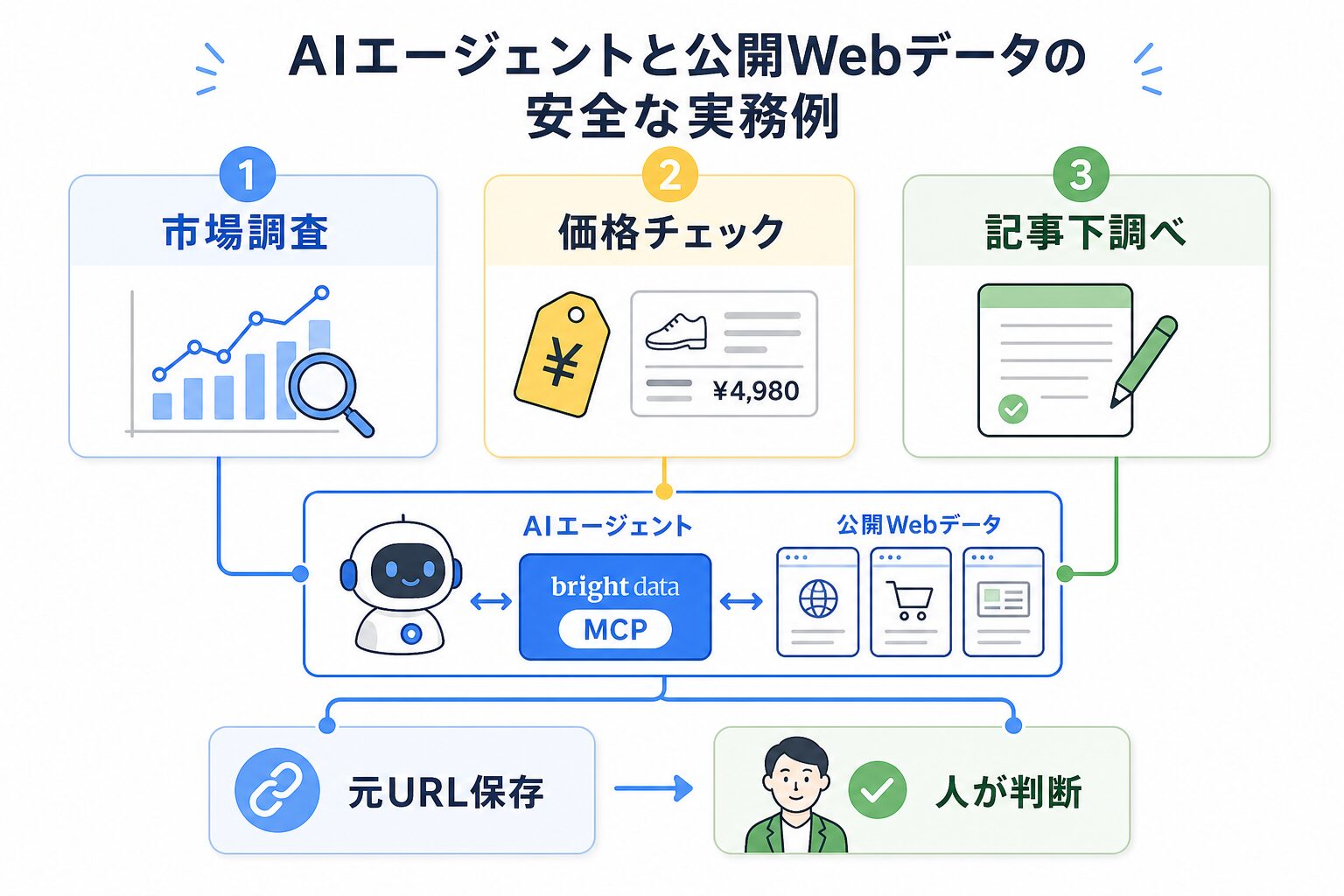
AIエージェントに渡すデータの形を決める
AIエージェントを使うときは、先に「何を渡すか」を決めると失敗しにくいです。公開ページの本文をそのまま長く渡すより、必要な項目をそろえた方が、後から読み返しやすくなります。
たとえば、記事下調べなら「取得日、タイトル、URL、発信元、要点、確認したい疑問」の6項目だけで十分です。価格チェックなら「取得日、商品名、価格、在庫表示、キャンペーン文言、URL」のようにします。お店のレシートを箱に放り込むのではなく、日付と金額を家計簿に写す感じです。
Bright Data MCPでは、検索系の入口、ページ内容をMarkdownやHTMLで受け取る入口、ブラウザ操作系の入口、構造化データ系の入口などを用途に応じて考えられます。初心者は、まず検索とページ取得のような分かりやすい範囲からで十分です。必要になってから、ECデータやブラウザ操作のような応用に進めば大丈夫です。
ここがポイントです。AIに渡すデータは、多ければよいわけではありません。少ない項目でも、元URL、取得日、見た目的な補足、確認メモがそろっていれば、仕事ではかなり使いやすくなります。
慣れてきたらどこまで広げられるのか
基本の流れが動くようになったら、n8nやGoogleスプレッドシートと組み合わせると使い道が広がります。たとえば、Bright Data MCPで取得した公開Webデータをn8nのワークフローに渡し、必要な項目だけスプレッドシートへ追加します。その後、週次でAIリサーチメモを作る流れです。
イメージとしては、調査、記録、要約を一列に並べる感じです。Bright Data MCPが公開Webデータの入口、n8nが作業をつなぐベルトコンベア、Googleスプレッドシートが台帳、AIリサーチメモが会議前の要約です。どれか1つで全部を解決しようとしない方が、仕組みは壊れにくくなります。
応用例としては、EC価格の週次チェックがあります。対象URLを決め、価格や在庫表示を取り、前週と違う行だけをスプレッドシートで目立たせます。AIエージェントには「変化があった商品」「キャンペーン文言が変わった商品」「人が確認すべきURL」を短くまとめてもらいます。
別の応用例として、ブログ記事の企画メモも作れます。検索結果や公式情報をもとに、初心者向けに説明が必要な用語、比較されやすい機能、実務例の候補を出してもらいます。ただし、最終的な主張や表現は人が確認します。AIの要約だけで事実扱いにせず、重要な箇所は元URLへ戻る流れを残しましょう。
逆に、これはやらない方がいいです
逆に、これはやらない方がいいです。ログイン後の画面、会員だけに見える情報、個人に深く関わる情報、サイトのルールに反する集め方を前提にしたAIエージェントです。AIが自動で動くほど、最初の境界線をあいまいにすると後で困ります。
たとえるなら、公開図書館の本を読んでメモするのは問題が少ない一方で、鍵のかかった部屋を開けようとするのは別の話です。Bright Data MCPを使う場合も、扱うのは公開Webデータの範囲に絞ります。公開情報でも、サイトの利用規約、robotsの案内、著作権、プライバシー、適用される法律は確認します。
また、AIエージェントに「できるだけたくさん集めて」とだけ指示するのも避けた方がいいです。仕事で使うなら、取得頻度、対象URL、保存期間、共有範囲、除外する情報を先に決めます。自動化は、ルールが決まっている作業を楽にするものです。ルールがない作業をそのまま速くすると、確認できない情報が増えてしまいます。
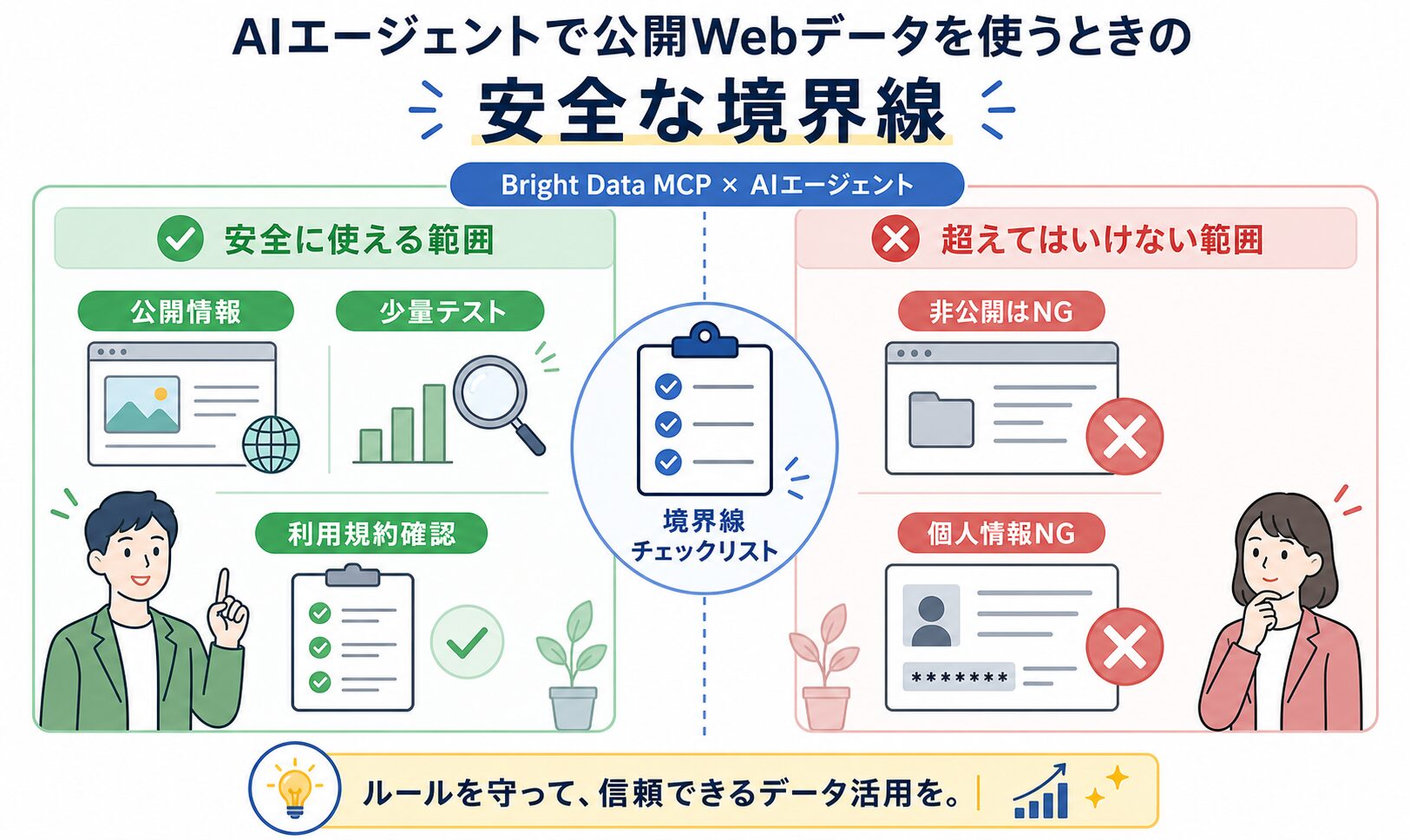
小さく始める手順
最初は、AIエージェントを大きく作らない方がうまくいきます。料理で言えば、いきなりフルコースを自動化するのではなく、まずは買い物メモを整えるところから始める感じです。
ここで大切なのは、AIエージェントの出力をそのまま正解にしないことです。最初の数回は、AIが出したメモと元URLを人が見比べます。ずれがあれば、対象ページ、項目名、指示文を直します。この調整ができてから、少しずつ対象を増やす方が安心です。
Bright Data MCPが向いている人・向いていない人
Bright Data MCPが向いているのは、AIエージェントに公開Webデータの材料を渡したい人です。市場調査、EC調査、SEO、記事下調べ、ブランド観測、AIリサーチを、毎週同じ形で続けたい場合は相性があります。
一方で、月に1回だけ手で検索すれば足りる人には大きすぎるかもしれません。その場合は、まず手作業のメモやRSS、ニュースレター、スプレッドシートから始めても十分です。道具を入れる前に、「この調査を何度も繰り返すのか」を見てください。
また、社内でデータの扱い方が決まっていない場合も、先にルール作りをした方がいいです。保存してよい情報、扱わない情報、確認する担当者、削除するタイミングを決めておくと、AIエージェントを使うときにも説明しやすくなります。
まとめ
Bright Data MCPは、AIエージェントに公開Webデータを渡すための入口として使える仕組みです。AIがすべてを判断する魔法ではありません。検索、ページ取得、構造化データ、ブラウザ操作のような道具を、調査目的に合わせてつなぎやすくするものです。
初心者は、まず1テーマ、5から10URL、週1回の小さな調査から始めるのがおすすめです。元URL、取得日、確認メモを残し、AIの要約は人が見直します。慣れてきたら、n8n、Googleスプレッドシート、BI、AIリサーチメモへ広げると、公開情報を仕事で使いやすい形に整えられます。
Bright Data MCPを使うときは、公開情報、少量テスト、利用規約の確認、人の最終判断をセットで考えてください。ここを押さえると、AIエージェントは怪しい自動化ではなく、調査の下準備を支える実務ツールとして使いやすくなります。