この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
BIダッシュボードを作るとき、意外とつまずくのはグラフの作り方ではありません。元になる表がバラバラなことです。EC価格は別のCSV、検索順位は手入力、レビュー数は誰かのメモ、競合ページの更新日は口頭だけ。これだと、きれいなグラフを作っても判断に使いにくいです。
Bright Dataは、ざっくり言うと、公開Webデータを仕事で扱いやすい形にそろえるための入口になります。公式サイトでも、Data FeedsやDataset Marketplace、Scraper APIなどを通じて、構造化された公開Webデータをワークフローへ渡す考え方が説明されています。BIとの相性がよいのは、ここです。BIは最後に見る画面で、その前に「同じ列名、同じ取得日、同じ基準」でデータを整える必要があります。
この記事では、データ分析やレポート作成をしたい初心者向けに、Bright Dataの公開WebデータをBIダッシュボードへつなげる考え方を整理します。最初に言っておくと、いきなり大きな分析基盤を作る必要はありません。まずは週1回、競合5商品や検索結果10件を表に残すところからで十分です。
– BIで見る前に公開Webデータを整える考え方
– Bright Data DatasetsやData Feedsが役立つ場面
– EC、SEO、広告、レビュー分析での具体例
– Google Sheets、Snowflake、BI、AIメモへ広げる流れ
– 公開Webデータを安全に扱う境界線
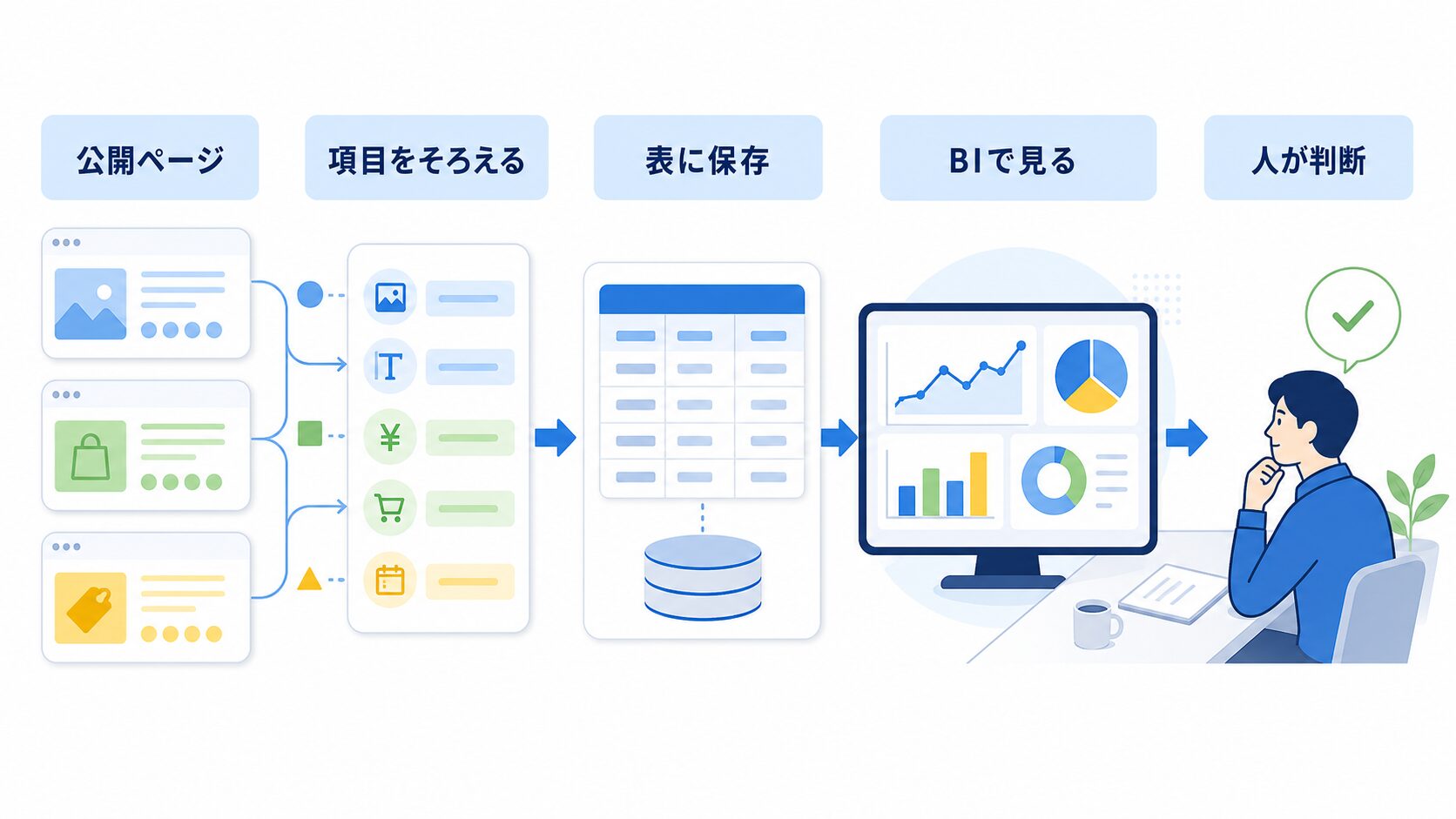
BIは「きれいなグラフ」より前の表づくりが大事
BIという言葉は少し難しく見えますが、初心者向けに言えば「仕事の数字や変化を、グラフや一覧で見やすくする画面」です。Google Looker Studio、Power BI、Tableau、社内ダッシュボードのようなものをイメージすると近いです。たとえるなら、倉庫の在庫を棚ごとに見えるようにした管理ボードです。
ただし、BIは元データが整理されていないと弱いです。商品名の表記が毎回違う、取得日が入っていない、価格と送料が混ざっている、在庫表示の言葉がそろっていない。こうなると、グラフは作れても「だから何を決めるのか」が見えません。ここでつまずきやすいです。
Bright DataのDataset Marketplaceでは、データのフィールド、サンプル、鮮度、カスタマイズ、配送先を確認しながらデータを選ぶ流れが案内されています。Data FeedsやScrapersでも、JSON、CSV、外部ストレージ、Webhookなどの配送先が用意されています。つまり、BIで使うには「どこから見るか」だけでなく、「どの形で受け取るか」も最初に決めます。
実務の小さい例なら、EC担当者が競合5商品の公開ページを週1回確認し、価格、在庫表示、レビュー数、キャンペーン文言、URL、取得日を1つの表に残します。この表をBIで見れば、価格差が広がった商品、在庫切れが続く競合、キャンペーン文言が変わったタイミングを見つけやすくなります。地味ですが、ここがポイントです。
Bright DataはBIの前段に置く「データをそろえる係」
Bright DataをBI連携で考えるときは、BIツールそのものの代わりと考えない方が分かりやすいです。Bright Dataは、公開Webデータを取得し、構造化し、必要に応じてCSV、JSON、クラウドストレージ、Snowflakeなどへ渡す前段の役割です。BIは、その後に人が見る画面です。
イメージとしては、料理の前の下ごしらえです。BIが盛り付けた料理だとすると、Bright Dataは材料を洗い、切り、同じサイズにそろえる係です。材料が大きすぎたり、泥がついていたり、種類が混ざっていたりすると、いくら盛り付けを工夫しても食べにくくなります。
たとえば、Bright DataのData Feeds公式ページでは、フィルターしたデータをAPI、Webhook、S3、Snowflake、Azure、直接ダウンロードなどへ渡す選択肢が説明されています。Dataset Marketplaceのドキュメントでも、データサンプル、項目、鮮度、購入オプション、配送先を確認する流れがあります。難しく聞こえますが、初心者は「BIに入れる前に、列をそろえて届ける仕組み」と考えれば十分です。
何を見るのか、どの項目を残すのか、どれくらいの頻度で見るのか、どこに保存するのか、誰が判断するのか。この5つを先に決めると、BI連携がかなり現実的になります。
ここでありがちな失敗は、いきなりSnowflakeやBIの設計から入ることです。もちろん必要な会社もあります。でも、最初の検証ならGoogle SheetsやCSVで十分です。週1回の表が1カ月続き、実際に会議や判断で使われてから、BIやデータウェアハウスへ広げる方が無駄が少ないです。
まずは「週次レポートに入れる3指標」から始める
初心者がBI連携を試すなら、最初は小さく始めるのが安全です。おすすめは、週次レポートに入れる3指標だけを選ぶことです。たとえばECなら、価格、在庫表示、レビュー数。SEOなら、検索順位、タイトル、URL。広告調査なら、広告文、表示URL、訴求カテゴリ。ここまでで十分です。
家計簿にたとえると、最初から全支出を細かく30分類しないのと同じです。まず食費、日用品、交通費くらいから始めます。続けられる形で残してから、必要に応じて分類を増やします。BIも同じで、最初から巨大なダッシュボードを作ると、見ないグラフが増えます。
実務では、マーケティング担当者が毎週月曜に競合3社の公開キャンペーンページを見ます。残す項目は、ページURL、見出し、割引表現、特典、取得日、メモ。結果はGoogle Sheetsに置き、BIでは「今週増えた訴求」「割引系の表現が多いカテゴリ」「自社LPで見直す候補」だけを見ます。ここで大事なのは、競合文をまねることではありません。市場の見せ方が変わっていないかを知る材料にすることです。
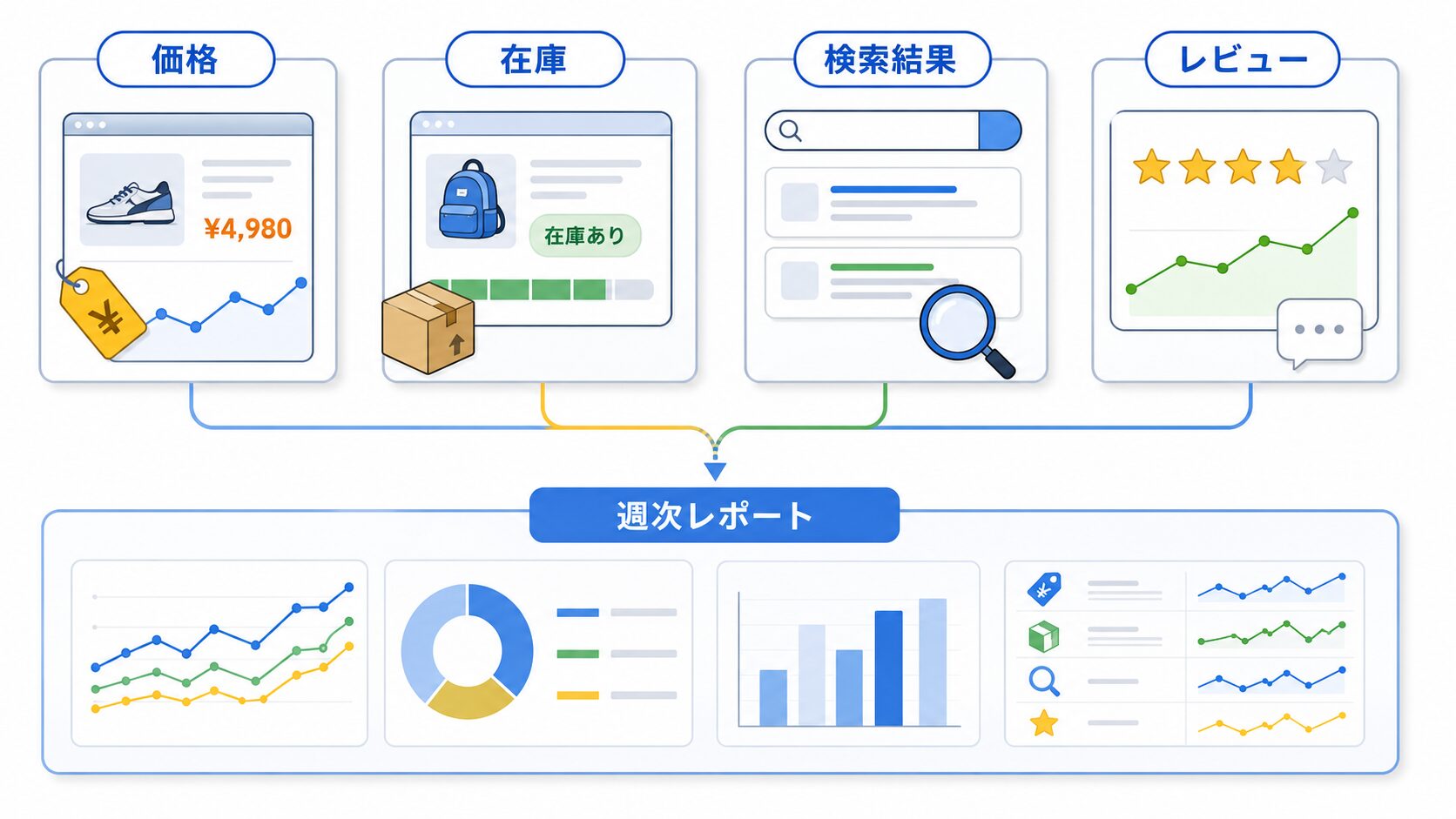
ここでつまずきやすいのは、「取れる項目を全部取った方が安心」と考えてしまうことです。商品説明全文、画像URL、すべてのレビュー本文、細かいランキング、SNS反応まで入れると、表が重くなり、見る人も疲れます。最初は、次の判断に使う列だけでいいです。少し物足りないくらいの方が続きます。
実務ではこう使えます
1つ目は、EC価格と在庫の週次ダッシュボードです。EC担当者が、自社の主力5商品と競合3社の公開商品ページを週1回見ます。価格、在庫表示、レビュー数、キャンペーン文言、URL、取得日を残し、BIで前週との差分を見ます。価格差が広がった商品は、値下げだけでなく、在庫訴求、送料表示、セット内容、広告文も確認します。注意点は、価格だけで判断しないことです。
2つ目は、SEO担当者の検索結果チェックです。SEO担当者が、重要キーワード20個について公開検索結果を月2回確認します。順位、タイトル、URL、表示される説明文、競合ドメイン、取得日を表にし、BIで順位変動とタイトル傾向を見ます。SERP APIを使う場合でも、目的は順位だけを見ることではありません。「どの記事をリライトするか」「新しく作るべき比較記事はあるか」を決める材料にします。
3つ目は、広告運用者の競合LP観察です。広告運用者が、競合の公開LPや検索広告で見える訴求を週1回整理します。見出し、価格訴求、無料体験、特典、対象ユーザー、URL、取得日を残し、BIや週次レポートで変化を見ます。店頭のポスターを見て「今月は初回割引が多いな」と気づく感覚です。ただし、相手の文章やデザインをそのままコピーするためではありません。
4つ目は、レビューや口コミの傾向確認です。商品担当者が、公開レビューの件数、星評価、よく出る不満カテゴリ、対象商品、取得日を月1回残します。BIでは、レビュー数が増えた商品、評価が下がったカテゴリ、説明不足が疑われる項目を見ます。ここは慎重に扱います。個人情報を拾いにいくのではなく、公開されている範囲で傾向を見るだけにとどめます。
5つ目は、メディア運営者のAIリサーチメモです。公開ニュースページや公式発表、競合ブログのタイトル、URL、公開日らしき情報、カテゴリ、取得日を整理し、BIではテーマ別の増減を見ます。その後、AIメモへ「今月増えたテーマ」「自社記事で不足している説明」「確認すべき元URL」を渡します。ここで元URLと取得日を残すのが大事です。AIの要約だけ残すと、あとで根拠を戻れなくなります。
どの例でも、先に「何の判断に使うのか」を決めます。価格を変えるのか、記事を直すのか、広告文を見直すのか、商品説明を補強するのか。Bright Dataでデータを集め、BIで見えるようにしても、最後に判断する人がいなければ、ただのきれいな画面で止まります。
慣れてきたらSheets、Snowflake、BI、AIメモへ広げる
基本の表が回るようになったら、保存先を少しずつ広げます。Bright Dataのドキュメントでは、DatasetsやScrapersのデータ配送先として、APIダウンロード、Webhook、S3、Google Cloud Storage、Azure、Snowflake、SFTPなどが案内されています。会社の規模や環境に合わせて選べるのが利点です。
最初はGoogle Sheetsで十分です。週1回、同じ列で追加していくだけでも、前週との差分は見えます。次に、行数が増えたり、部署で共有したり、BIで自動更新したくなったら、クラウドストレージやSnowflakeのような保存先を検討します。ここは少し迷いやすいですが、順番としては「使われる表を作る」方が先です。
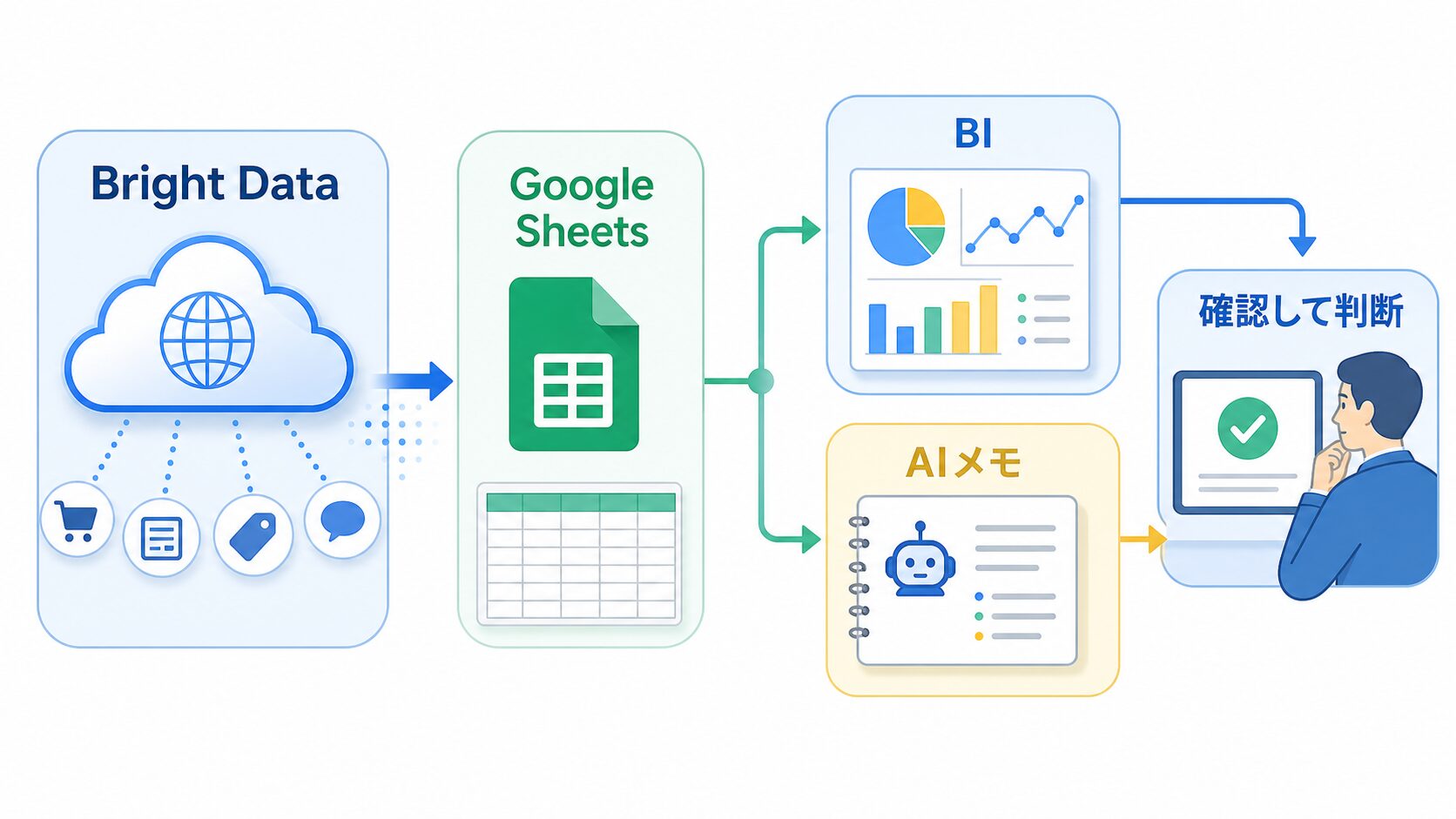
応用例としては、n8nで週1回の処理を組み、Bright Dataから受け取った公開データをGoogle Sheetsへ追記し、BIでダッシュボード化し、変化が大きい行だけAIリサーチノートへ送る流れがあります。たとえば、競合商品の価格が10%以上変わった、検索結果の上位URLが入れ替わった、レビュー数が急に増えた、広告LPの見出しが変わった。こういう行だけ人が見るようにします。
正直、最初から全自動にしなくていいです。人が見るべき行だけを減らす。このくらいの考え方が現実的です。BIは毎日眺めるものではなく、会議前、月初、キャンペーン前など、判断するタイミングに合わせて見る方が使われます。
安全に使うための境界線
Bright DataをBI連携で使う場合も、対象は公開Webデータに絞ります。サイトの利用規約、robotsの考え方、プライバシー、適用される法律を確認します。ログイン後の画面、会員限定情報、個人情報、相手サイトに負荷をかける頻度の取得は避けます。
たとえるなら、店頭に出ている価格表を見てメモするのは市場調査です。でも、店のバックヤードに入って仕入れ台帳を見るのは別の話です。Webでも同じです。公開ページの価格、タイトル、在庫表示、レビュー件数を見ることと、非公開情報へアクセスしようとすることはまったく違います。
非公開ページ、ログイン後の画面、個人情報の不適切な収集、スパムやアカウント悪用、相手サイトに迷惑な高頻度アクセスには使わないでください。最初は小さい範囲、控えめな頻度、公開情報だけで試すのが安全です。
もう1つの注意点は、BIの数字をそのまま正解にしないことです。公開ページにはセール期間、地域差、在庫切れ、表記ゆれ、取得エラーがあります。BIで赤く表示されたからすぐ値下げする、検索順位が下がったからすぐ記事を削る、という使い方は危ないです。数字はきっかけです。最後は元URLを見て、人が確認します。
Bright DataのBI連携が合う人、まだ早い人
合うのは、公開Webデータを定期的に見ているのに、表やレポートが毎回バラバラな人です。EC担当者、SEO担当者、広告運用者、メディア運営者、商品担当者、データ分析担当には検討しやすいです。特に、毎週同じページを見ているのに判断メモが残らない場合は、BI化の前にデータのそろえ方を見直す価値があります。
反対に、月に1回だけ2、3ページを見る程度なら、まだ手作業で十分かもしれません。まずはGoogle Sheetsで、URL、項目、取得日、判断メモを残す。1カ月続けて、実際に会議や改善で使われたかを見る。そこまでやってから、Bright Data、クラウド保存、BI連携を考える方が無駄が少ないです。
つまり、Bright DataとBIの組み合わせは「大きな会社だけの難しい分析」ではありません。小さく始めるなら、週1回、公開ページ、3指標、1つの表。慣れてきたら、Google Sheets、BI、AIメモ、Snowflakeへ広げる。この順番なら、初心者でもかなりイメージしやすくなります。
まとめ
Bright Dataの公開WebデータをBIダッシュボードで使うときは、最初から大きな分析基盤を作る必要はありません。大事なのは、BIに入れる前の表づくりです。何を見るのか、どの項目を残すのか、どれくらいの頻度で見るのか、どこに保存するのか、誰が判断するのか。この順番を決めるだけで、かなり現実的になります。
最初は、EC価格、在庫表示、検索結果、レビュー数、広告LPの見出しなど、週次レポートで使う項目に絞ります。Google Sheetsで動くようになってから、BIやSnowflake、AIリサーチメモへ広げます。きれいなグラフを作る前に、同じ列名、同じ取得日、同じ判断メモを残す。ここが地味ですが、あとで効きます。
そして、対象は公開情報だけに絞ります。規約や法律を確認し、小さく試し、人が最後に元URLを見て判断する。Bright Dataは、BIを魔法の答え箱にする道具ではありません。公開Webデータを見える形にそろえ、仕事の判断材料を増やすための入口です。