この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
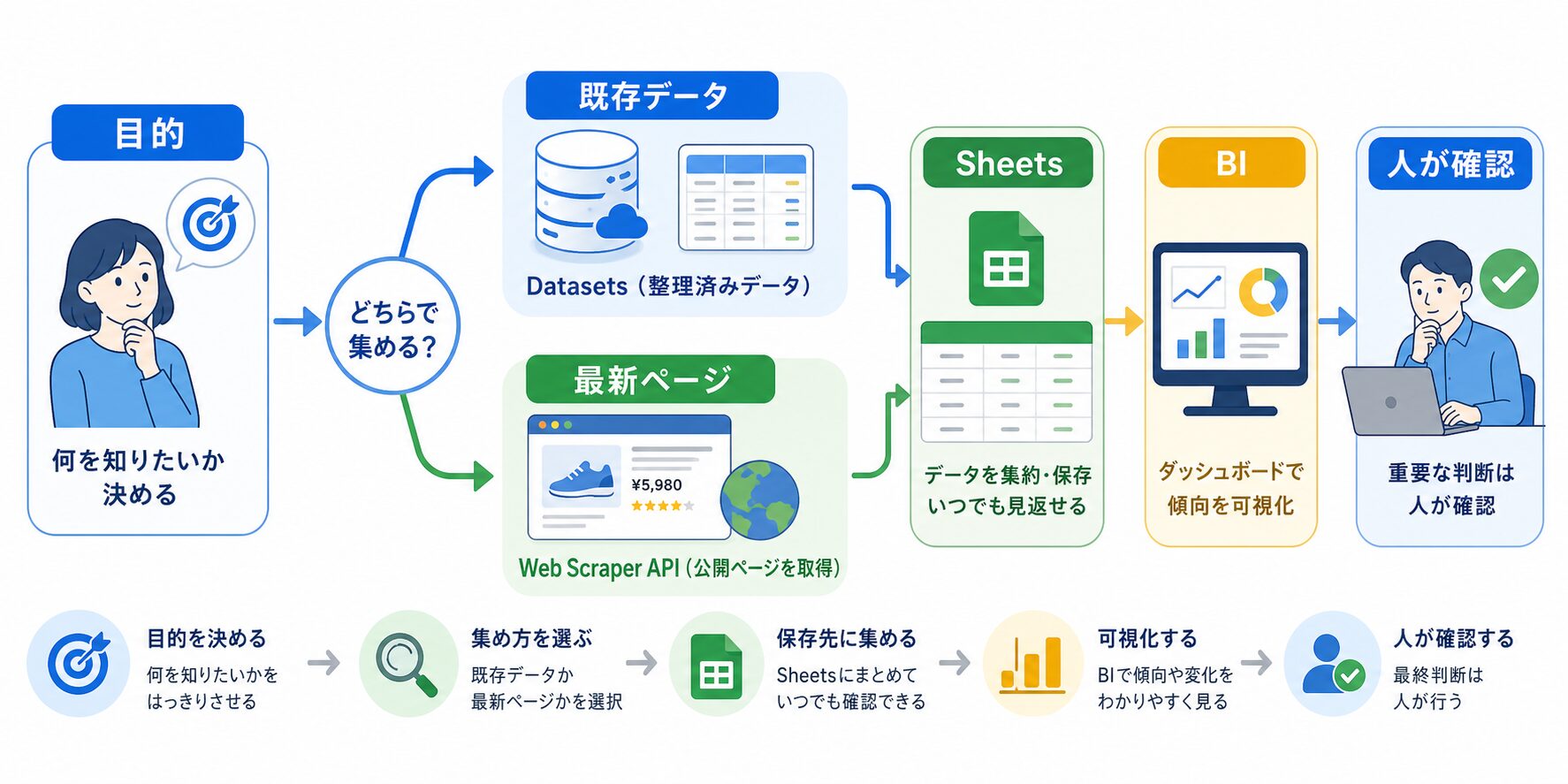
データを使って市場調査やAIリサーチをしたい。でも、Bright Dataのページを見ると「Datasets」も「Web Scraper API」も出てくる。ここで一度迷う人は多いはずです。
結論から言うと、Datasetsは整理済みのデータを受け取る選択肢、Web Scraper APIは公開ページから必要な項目を自分の条件で集める選択肢です。イメージとしては、Datasetsが「すでに仕込みが終わった食材セット」、Web Scraper APIが「必要な材料を店頭で見て買い集める係」です。
たとえば、EC市場全体の価格帯や商品数をざっくり見たいなら、最初から整ったDatasetsが合うことがあります。反対に、競合10商品の価格・在庫表示・キャンペーン文言を毎週月曜に確認したいなら、Web Scraper APIの方が考えやすいです。どちらが上というより、知りたいことの形が違うと見るのが近いです。
– DatasetsとWeb Scraper APIの役割の違い
– 初心者がどちらから試すべきか
– EC、マーケティング、AIリサーチでの使い分け
– Google Sheets、n8n、BIへ広げる考え方
– 公開Webデータを安全に扱う境界線
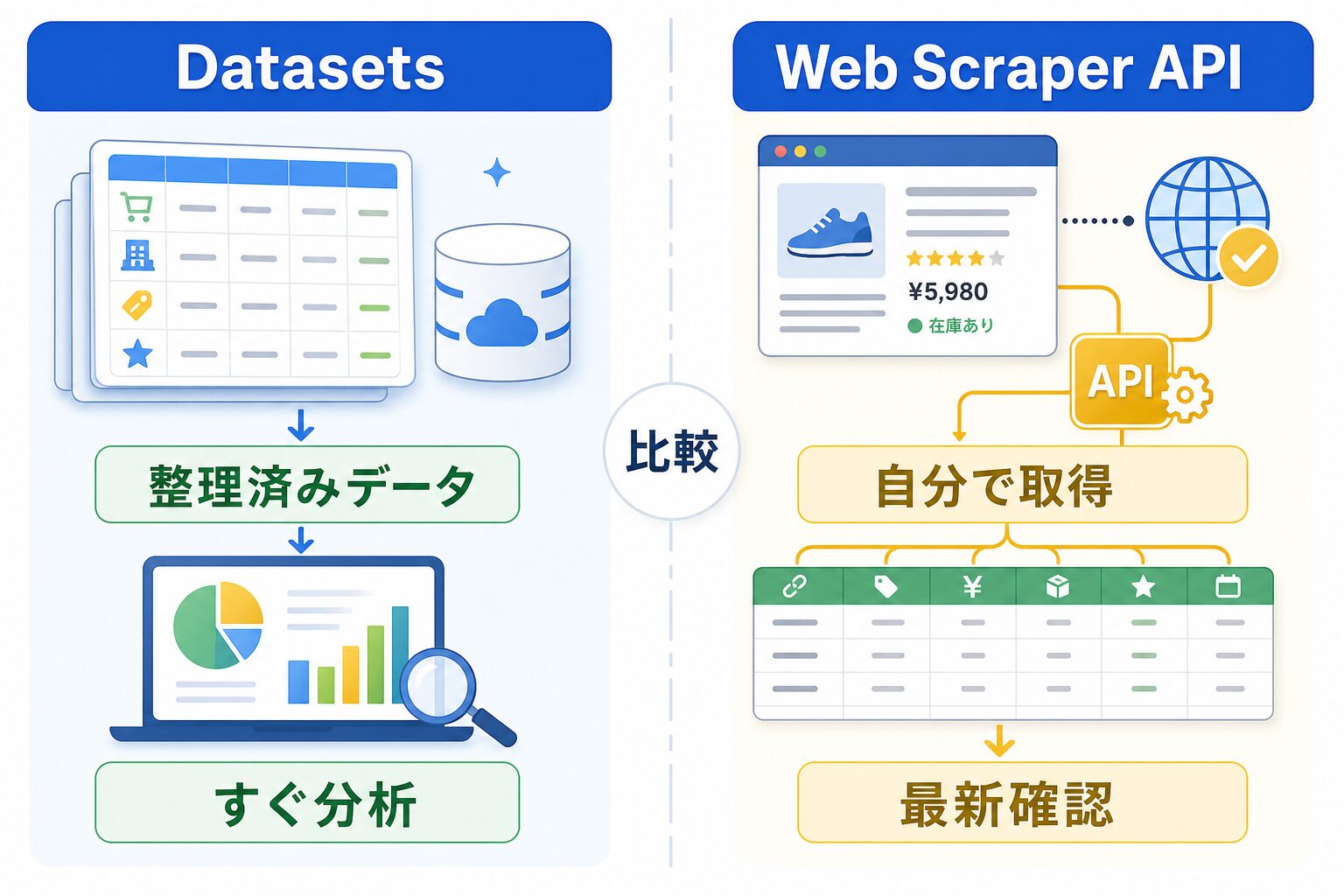
まず違いは「完成品を受け取るか、取りに行くか」
Datasetsは、公開Web上の情報をもとに、すでに表として使いやすい形へ整えられたデータです。Bright Dataの公式ページでも、Datasetsは120以上の人気サイトからのクリーンで検証済みのデータを、AI、市場調査、ビジネス用途に使える形で提供すると説明されています。ざっくり言うと、データ収集の面倒な準備をかなり済ませた状態で受け取るものです。
一方、Web Scraper APIは、公開ページから新しい構造化データを取り出すための入口です。公式ドキュメントでは、すぐ結果を受け取る同期処理と、複数件や大きめの取得に向いた非同期処理が案内されています。つまり、今見たいページに対して「この項目を取ってきて」と頼む道具です。
身近なたとえなら、Datasetsはスーパーのカット野菜や下味済みの食材セットに近いです。すぐ調理に入れます。Web Scraper APIは、必要な野菜を売り場で選び、量や種類を自分で決める作業に近いです。自由度は高いですが、何を買うかを先に決める必要があります。
Datasetsが向いているのは、広めの調査を早く始めたい場面
Datasetsが向いているのは、商品、企業、求人、不動産、レビューなど、まとまったデータを先に手元へ置きたい場面です。たとえばEC担当者が「このカテゴリの価格帯を見たい」「レビュー数が多い商品を並べたい」「競合商品のだいたいの分布を知りたい」と考えるとします。この場合、1ページずつ見に行くより、整理済みの表から始めた方が早いことがあります。
これは、旅行前に地図帳を買って全体像を見る感覚に近いです。1軒ずつ現地を歩けば細かい情報は分かりますが、まず地域全体の位置関係を見たいなら地図帳が便利です。Datasetsも同じで、広めの市場感、カテゴリごとの傾向、AIに渡す基礎データを作るときに候補になります。
実務例で言うと、メディア運営者が月初にECカテゴリの公開商品データを見て、商品名、価格帯、レビュー数、カテゴリ、更新時期を確認します。その結果をGoogle SheetsやBIに入れ、来月の記事テーマを「価格が動いているカテゴリ」「レビューが増えている商品群」から選ぶ。最初はここまで分かれば十分です。
ここでつまずきやすいのは、「整理済みなら何でも答えが出る」と考えることです。Datasetsは便利ですが、取得時点のデータです。フィールドの意味、更新頻度、対象サイト、サンプルデータを見て、自分の判断に使える列があるかを確認します。古い地図だけで今日の渋滞を判断しないのと同じです。
Web Scraper APIが向いているのは、今の公開ページを見たい場面
Web Scraper APIが向いているのは、対象ページと取りたい項目がかなりはっきりしている場面です。たとえば、競合10商品の公開ページを毎週月曜に見て、価格、在庫表示、レビュー数、キャンペーン文言、取得日をGoogle Sheetsへ残す。こういう作業は、Web Scraper APIの方が自然です。
イメージとしては、店頭の値札を決まった曜日に確認する係です。Datasetsが「まとめて届く市場データ」だとしたら、Web Scraper APIは「今週の売り場を見に行く係」です。公式情報でも、Web Scraper APIは新しい構造化Webデータを抽出し、コードやプロキシ管理の負担を減らす方向で案内されています。
初心者が最初に試すなら、5URLからで十分です。URL、商品名、価格、在庫表示、キャンペーン文言、取得日。この6列だけを表にします。いきなり50項目を取ろうとすると、どれが仕事に必要だったのか分からなくなります。最初は、判断に使う列だけでいいです。
ただし、Web Scraper APIも「好きなページを何でも取っていい道具」ではありません。対象は公開ページに絞り、サイトのルール、robotsの考え方、プライバシー、適用される法律を確認します。頻度も控えめに始めます。店頭価格を見るのと、店の裏側の帳簿を見ようとするのはまったく別です。
選び方は「何を知りたいか」から決める
機能名から考えると難しく見えますが、仕事の目的から逆算するとかなり楽になります。市場全体の傾向、商品群の分布、AIに渡す基礎データを早く整えたいならDatasets。指定した公開ページの今の状態を、同じ条件で繰り返し見たいならWeb Scraper APIです。
たとえば、EC運営者が「競合カテゴリの価格帯を把握したい」ならDatasetsが候補になります。広い棚を一度に眺める作業だからです。逆に「先週と比べて、競合A社の商品ページの価格と在庫表示が変わったか知りたい」ならWeb Scraper APIです。これは、特定の棚の値札を見に行く作業だからです。
料理でたとえると、Datasetsはレシピ付きのミールキットです。早く全体を作れます。Web Scraper APIは市場へ買い出しに行くことです。自由に選べますが、買うものリストがないと迷います。どちらも役に立ちますが、使う場面が違います。
普通の仕事ではこう使い分ける
1つ目は、EC市場の下調べです。EC担当者が月初にDatasetsを使い、対象カテゴリの商品名、価格帯、レビュー数、ショップ名、更新時期を確認します。結果はBIに入れて、価格帯の偏りやレビューが多い商品群を見ます。次の仕入れや記事テーマを考える材料になります。注意点は、データの更新日と対象範囲を必ず見ることです。
2つ目は、競合商品の価格と在庫表示の定点観測です。EC運営者が競合10商品の公開ページをWeb Scraper APIで週1回確認し、価格、在庫表示、セール文言、レビュー数、取得日をGoogle Sheetsへ残します。前週と差が出た商品だけ、人がページを開いて見ます。スーパーの値札を同じ曜日にメモする感覚です。注意点は、頻度を上げすぎず、サイトのルールを確認することです。
3つ目は、AIリサーチの材料作りです。AIリサーチ担当者がDatasetsで企業や商品の基礎データを用意し、Web Scraper APIで直近の公開ページだけ補足します。そのうえで、AIメモに「今月増えた傾向」「価格帯が変わった商品群」「確認すべき元URL」を整理させます。学校のレポートで、参考文献リストと最新ニュースを分けて集めるようなものです。注意点は、AIの要約を結論にせず、元URLと取得日へ戻れる形にすることです。
4つ目は、広告やキャンペーンの確認です。マーケティング担当者がDatasetsでカテゴリ全体の主要商品を見つけ、Web Scraper APIで競合の公開キャンペーンページを週1回確認します。見たい項目は見出し、価格訴求、キャンペーン期間、URL、取得日くらいで十分です。広告文をまねるためではなく、自社の訴求が古くなっていないかを見直す材料にします。
慣れてきたら「基準はDatasets、変化はWeb Scraper API」にできる
基本の使い分けが分かってきたら、両方を組み合わせる考え方もあります。ここがポイントです。Datasetsで市場の基準を作り、Web Scraper APIで直近の変化を見る。そうすると、広い地図と今日の現地確認を分けて扱えます。
たとえば、月初にDatasetsでカテゴリ全体の商品一覧と価格帯をBIへ入れます。毎週はWeb Scraper APIで、重要な20商品だけ価格、在庫表示、キャンペーン文言をGoogle Sheetsへ追記します。n8nを使うなら、毎週月曜の朝に取得し、前週との差分が大きい行だけSlackやAIリサーチノートへ送る流れも作れます。
ただ、最初からn8n、BI、AIメモまで全部つなぐ必要はありません。まずは1カテゴリ、5商品、週1回。表の列が固まってから自動化へ広げる方が、後で直す手間が少なくなります。引っ越し前に収納棚を買いすぎると困るのと同じで、先に荷物の量を見た方がいいです。
もう少し進めるなら、Datasetsを「月次の土台」、Web Scraper APIを「週次の確認」と分けます。BIでは月次の価格帯、レビュー数、商品数の変化を見る。Google Sheetsでは週次の個別商品変化を見る。AIには、両方を混ぜずに「月次の傾向」と「週次の変化」を別々に要約させると、判断しやすくなります。
逆に、これはやらない方がいいです
逆に、これはやらない方がいいです。取れるデータを全部取り、AIにそのまま結論を出させることです。データは材料であって、答えそのものではありません。価格、レビュー数、在庫表示、キャンペーン文言も、取得日や対象範囲が抜けると後で意味が分からなくなります。
もう1つ避けたいのは、公開情報の範囲を超える使い方です。Bright DataのAcceptable Use Policyでは、非公開情報の収集、DDoS、スパム、広告不正、なりすまし、偽アカウント作成などの不正・悪用は禁止されています。ログイン後の画面、個人情報の不適切な収集や保存、迷惑な高頻度アクセスには使わないでください。
身近なたとえなら、公開されているチラシを見て価格を比較するのは普通の調査です。でも、関係者しか見られない台帳を見ようとするのは別の話です。Bright Dataを使うときも、公開Webデータ、規約確認、少量テスト、人の確認。この4つを先に置いておくと、変な方向へ進みにくくなります。
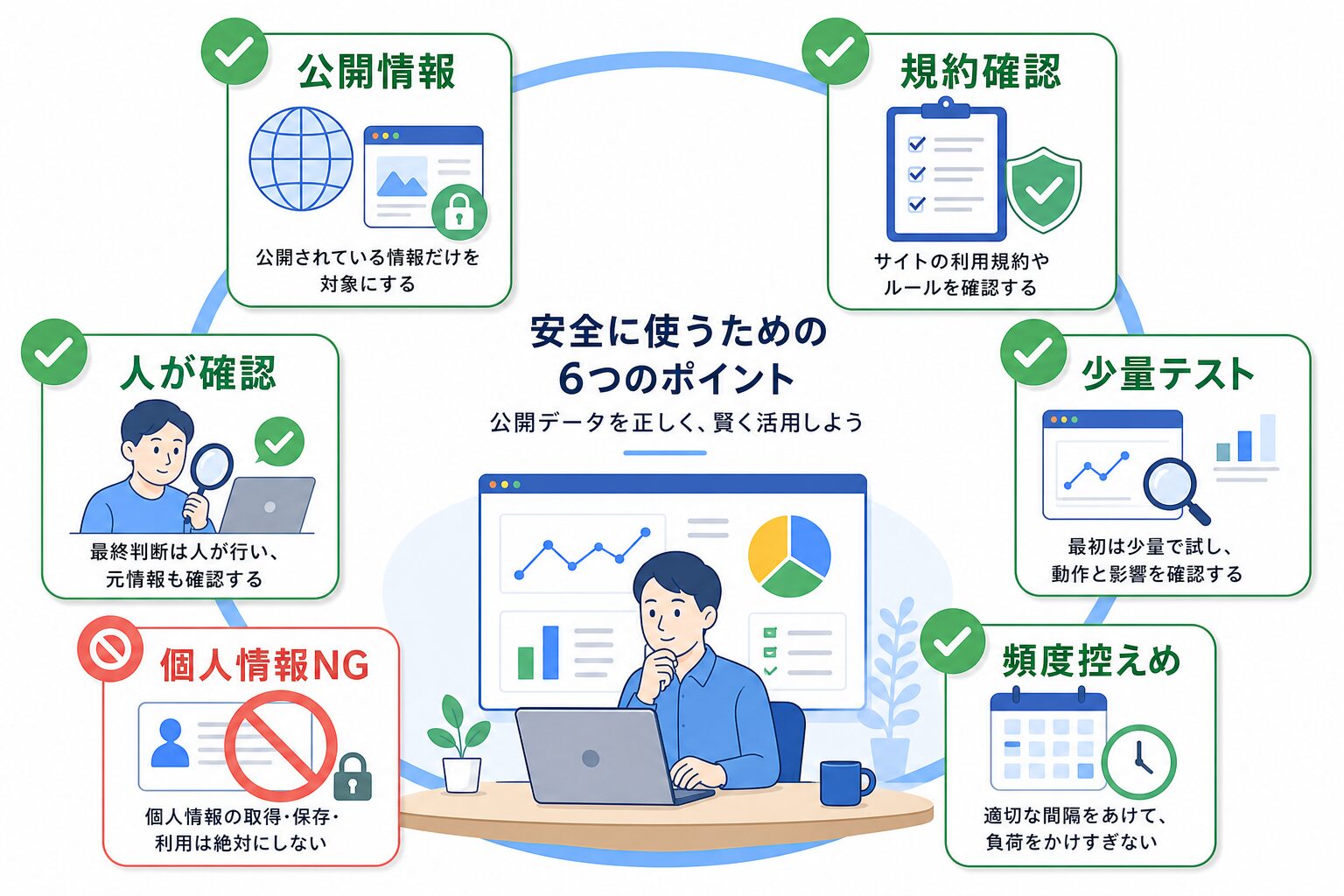
対象は公開Webデータに絞ります。サイト規約、robotsの考え方、プライバシー、適用される法律を確認し、少量から試してください。非公開情報、個人情報の不適切な取得や保存、スパム、アカウント悪用、不正アクセスには使わないでください。
Bright Dataが合う人、まだ早い人
Bright Dataが合うのは、公開Webデータを継続して仕事の判断材料にしたい人です。EC担当者、マーケティング担当者、メディア運営者、AIリサーチ担当者、データ分析担当者のように、同じ項目を毎週または毎月見たい人には向いています。
反対に、月に1回だけ数ページを見る人なら、最初は手作業とGoogle Sheetsで十分かもしれません。道具を入れる前に、どのページを見るのか、どの列を残すのか、どの頻度で見るのか、結果を何の判断に使うのかを決める方が先です。家計簿アプリを入れる前に「食費を見たいのか、固定費を見たいのか」を決めるのと同じです。
DatasetsとWeb Scraper APIは、どちらか一方だけを選ぶものではありません。最初はDatasetsで広く見て、必要なページだけWeb Scraper APIで定点観測する。あるいは、まずWeb Scraper APIで5URLを試し、もっと広く見たくなったらDatasetsを検討する。このくらいの順番で大丈夫です。
まとめ
DatasetsとWeb Scraper APIの違いは、難しく考えすぎなくて大丈夫です。Datasetsは、整理済みのデータを受け取って、広めの調査やAIリサーチの土台にしやすい選択肢です。Web Scraper APIは、指定した公開ページから今の情報を取り出し、価格、在庫表示、レビュー数、キャンペーン文言などを定点観測しやすい選択肢です。
市場全体を早く見たいならDatasets。特定ページの変化を同じ条件で追いたいならWeb Scraper API。慣れてきたら、Datasetsを月次の土台、Web Scraper APIを週次の変化確認として分けると、Google Sheets、n8n、BI、AIリサーチノートへ広げやすくなります。
最初は小さくて十分です。Datasetsならサンプルとフィールド確認から。Web Scraper APIなら5URL、週1回、必要な列だけ。公開情報に絞り、規約を確認し、取得日と元URLを残し、人が最後に見る。この順番なら、初心者でもBright Dataの使い分けを無理なく始められます。