

この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
Webデータを集めたいと思っても、最初につまずくのは「コードを書けないと無理なのでは?」というところだと思います。商品名、価格、レビュー数、URLくらいを表にしたいだけなのに、いきなりプロキシ、JavaScript、セレクタ、実行環境の話になると、ちょっと遠く感じますよね。
Bright Data Scraper Studioは、そこを少し手前に戻してくれる機能です。ざっくり言うと、公開ページから取りたい項目をAIに説明し、スクレイパー作成の入口を作るための作業場です。イメージとしては、最初から職人道具を全部渡されるのではなく、店員さんに「この棚から商品名と価格だけ表にしたいです」と相談しながら買い物リストを作る感じです。
もちろん、何でも丸投げで完璧になるわけではありません。ここがポイントです。Scraper Studioで大事なのは、AIに任せることよりも、どの公開ページから、どの項目を、何の判断に使うのかを人間側が決めることです。この記事では、コードを書かずにWebデータ収集を試したい初心者向けに、Scraper Studioで何ができるのか、どこから始めればいいのか、逆に何をやらない方がいいのかを整理します。
– Bright Data Scraper Studioの基本的な役割
– AI AgentとIDEの違い
– 初心者が最初に試す小さな使い方
– EC、マーケティング、AIリサーチでの実務例
– Google Sheets、n8n、AIメモへ広げる考え方
Scraper Studioは「公開ページを表にする作業場」
Scraper Studioは、Bright Dataの中でカスタムスクレイパーを作るためのクラウド上の作業場です。スクレイパーというのは、Webページを見に行き、必要な項目を表の形に取り出すための処理です。難しく聞こえますが、やっていることは「ページを見る」「必要な場所を読む」「表にする」の3つに分けられます。
身近なたとえなら、チラシを見て、商品名、価格、キャンペーン期間をノートに写す作業です。手で1枚ずつ見るなら簡単ですが、毎週同じページを見たり、10商品分を比べたりすると地味に大変です。Scraper Studioは、そのメモ係を作る場所だと考えると分かりやすいです。
Bright Dataの公式ドキュメントでは、Scraper StudioはAI AgentとJavaScriptエディタを備えたクラウドIDEとして説明されています。ページを操作する部分と、HTMLから項目を取り出す部分を扱い、結果はJSON、CSV、NDJSON、XLSXなどの形で確認できます。最初は形式名まで覚えなくて大丈夫です。表として後で見返せる形にできる、と理解すれば十分です。
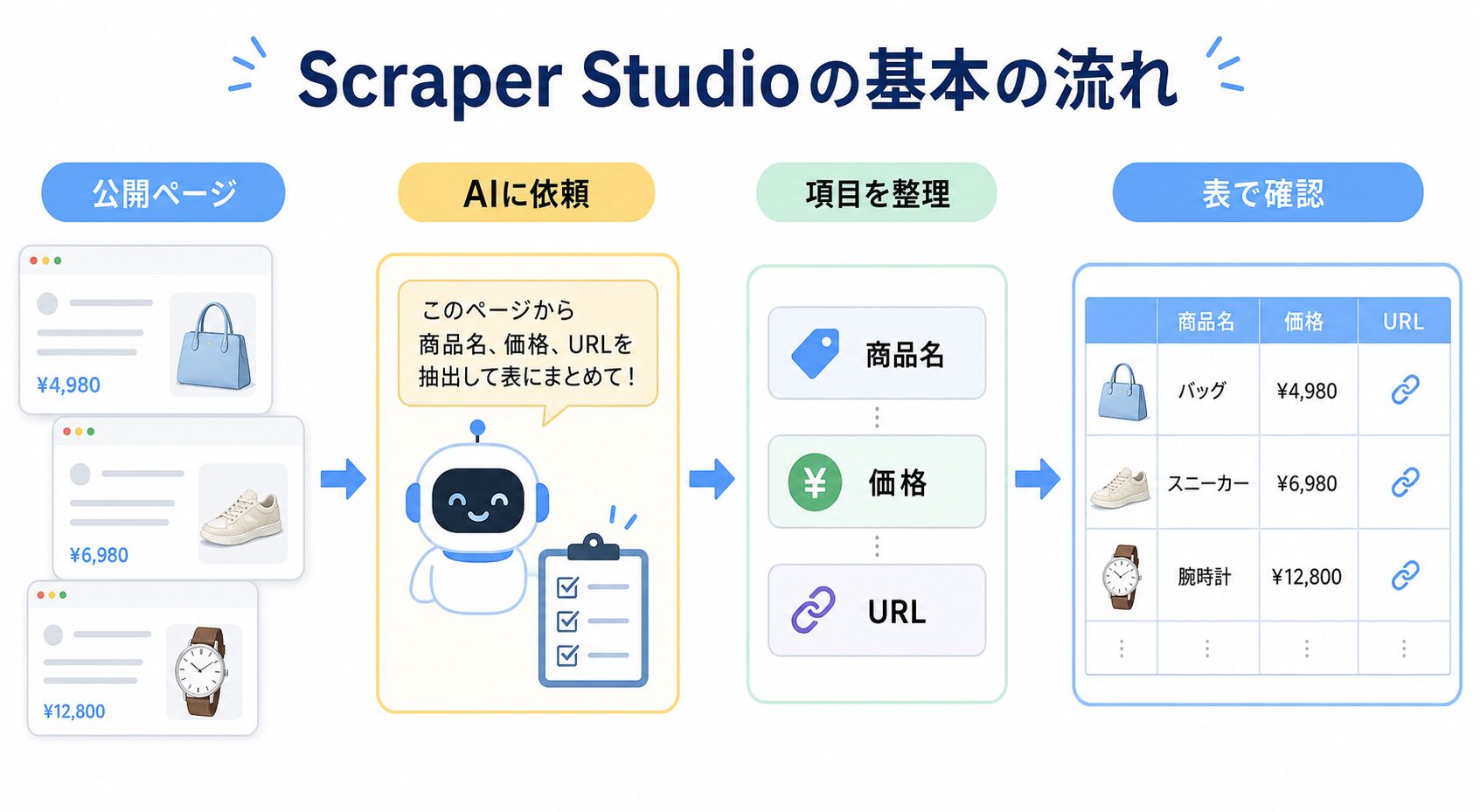
ここでつまずきやすいのは、「AIがスクレイパーを作るなら、ページURLだけ渡せばよさそう」と思ってしまう点です。実際には、欲しい項目をかなり具体的に伝えるほど精度を上げやすくなります。たとえば「商品名、価格、在庫表示、レビュー数、URL、取得日を表にしたい」と言うだけで、AI側の迷いはかなり減ります。
AI AgentとIDEは、入口の違いです
Scraper Studioには、AI AgentとIDEという2つの作り方があります。AI Agentは、自然な文章で「このページからこの項目を取りたい」と伝えて、出力項目の設計やコード作成を手伝ってもらう入口です。IDEは、JavaScriptを書いて細かく調整する入口です。
イメージとしては、AI Agentが「相談できる受付」、IDEが「奥の作業台」です。最初は受付で希望を伝え、だいたいの形を作る。あとで細かく直したくなったら作業台に移る。公式ドキュメントでも、AI Agentで作ったスクレイパーはScraper Studio IDEで直接編集できると説明されています。つまり、最初にAI Agentを使ったらずっとノーコードのまま固定、という話ではありません。
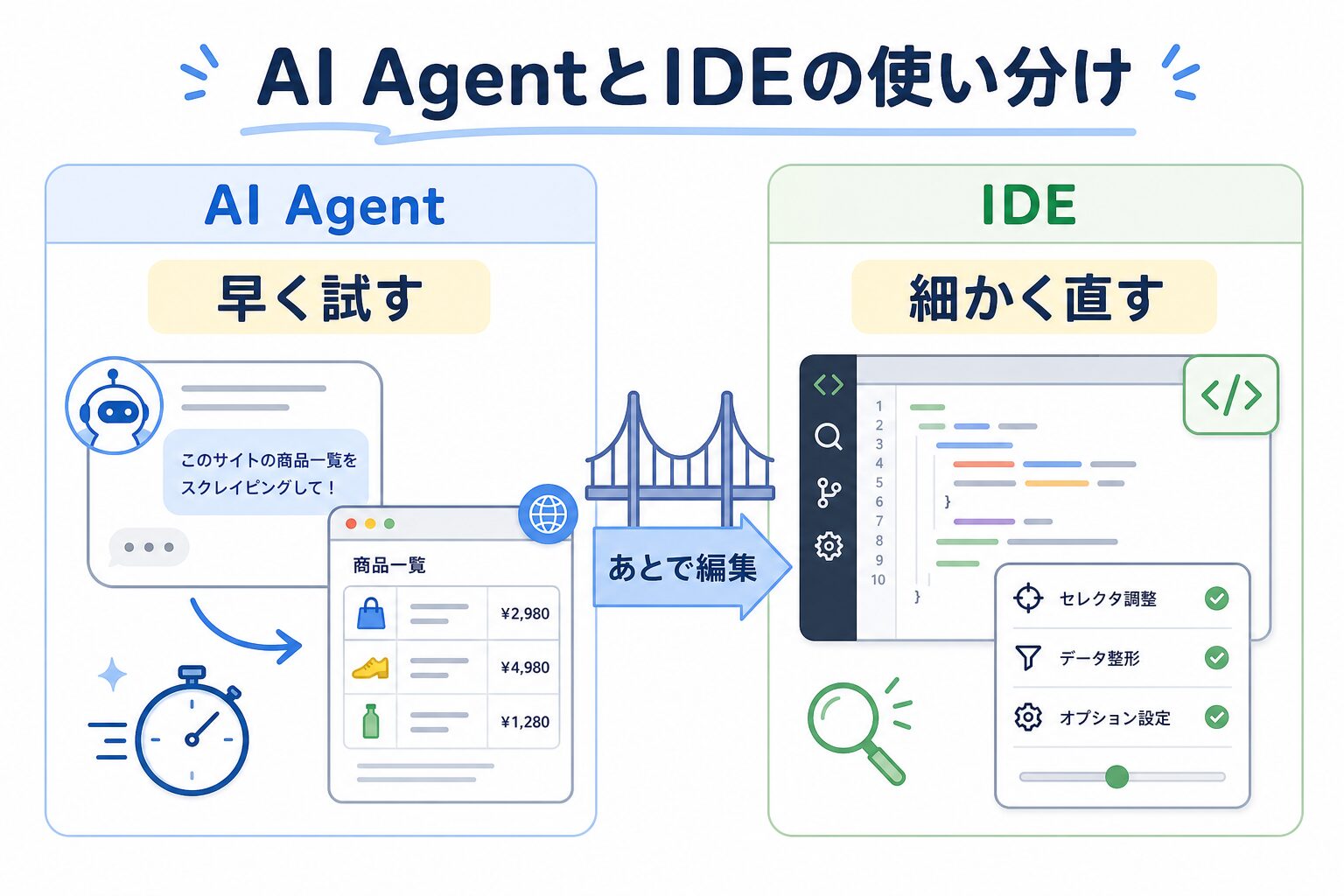
初心者なら、最初はAI Agentで十分です。たとえばEC担当者が、競合商品の公開ページを5URLだけ用意します。AI Agentに「商品名、価格、在庫表示、レビュー数、URLを取りたい。結果は表で確認したい」と伝えます。AIが出力項目の形を作ったら、人間が「画像URLはいらない」「セール文言を追加したい」と直します。この確認が地味に大事です。
一方、IDEが向いているのは、クリックやページ移動が多いサイト、複数段階の処理が必要なサイト、取得項目の条件分岐を細かく書きたい場面です。料理で言えば、AI Agentはレシピを一緒に作ってくれる人、IDEは自分で火加減まで調整するキッチンです。いきなりキッチンに立たなくてもいいですが、複雑な料理では最後に人の調整が必要になります。
最初は「5ページ・5項目・週1回」で十分です
Scraper Studioを試すとき、最初から大きな自動化を作ろうとしない方がいいです。おすすめは、5ページ、5項目、週1回です。たとえば、競合5商品の公開ページから、商品名、価格、在庫表示、レビュー数、URLを取り、Google Sheetsへ貼れる形で確認します。
これは、毎朝いきなり市場全体を調べるのではなく、近所のスーパーで同じ5商品の値札を週1回見る感覚です。小さいですが、仕事にはかなり効きます。前週と比べて価格が変わったのか、在庫表示が変わったのか、キャンペーン文言が変わったのか。そこだけ見えれば、値下げするのか、商品ページの見せ方を変えるのか、広告文を見直すのかを考えやすくなります。
AI Agentに頼む文章も、最初は短くてかまいません。ただし、曖昧すぎると結果も曖昧になります。たとえば「このサイトをスクレイプして」ではなく、「この5つの商品ページから、商品名、税込価格、在庫表示、レビュー数、URLを取り、1行1商品で出したい」と言う方が実務に近いです。
ここで迷いやすいのは、取れる項目を全部取りたくなることです。でも、最初はここまで分かれば十分です。列が増えすぎると、後で人が見なくなります。使う予定のない列は、きれいなゴミになりがちです。
仕事ではこう使えます
1つ目は、EC価格チェックです。EC担当者が毎週月曜の朝に、競合5商品の公開ページを確認します。見る項目は商品名、価格、在庫表示、レビュー数、キャンペーン文言、URL、取得日です。結果はGoogle Sheetsに残し、前週との差が大きい商品だけ人がページを開きます。注意点は、対象を公開ページに絞り、頻度を上げすぎないことです。
2つ目は、競合キャンペーンの確認です。マーケティング担当者が、競合の公開キャンペーンページやLPを週1回見ます。見たい項目は見出し、価格訴求、期間、特典、URL、取得日くらいで十分です。これは、駅前のポスターを定期的に写真で残しておく感覚に近いです。目的はまねることではなく、自社の訴求が古くなっていないかを見直す材料にすることです。
3つ目は、記事やAIリサーチの下調べです。メディア運営者が、公開されているニュースページや公式発表ページを対象に、タイトル、公開日、会社名、URL、要約メモを集めます。結果はAIリサーチノートに入れ、月末に「よく出てきたテーマ」「古くなった記事」「追記すべき話題」を整理します。ここで大事なのは、AIの要約だけで判断しないことです。元URLと取得日へ戻れる形にします。
4つ目は、レビュー傾向の確認です。商品担当者が公開レビュー一覧を少量だけ見て、レビュー件数、星評価、よく出る不満の言葉、対象商品、取得日をメモします。全部を自動で結論にするのではなく、改善会議の前に「どの商品を先に見るか」を決める材料にします。これは、アンケートの山から付箋を先に分けるような作業です。
どの例でも共通するのは、先に「人が何を判断するか」を決めておくことです。Scraper Studioは表を作る道具ですが、判断そのものを丸投げする道具ではありません。価格を見たあとに値下げするのか、訴求を変えるのか、商品ページを直すのか。そこは人間側の仕事です。
慣れてきたらn8nやSheets、AIメモへ広げる
基本の流れが動いたら、次に広げる先はGoogle Sheets、n8n、BI、AIリサーチノートです。たとえばScraper Studioで週1回データを取り、Google Sheetsに保存します。n8nで前週との差分を見て、価格が大きく変わった行だけSlackやメールに送ります。最後にAIメモへ「今週見るべき商品3つ」を要約させる。こうすると、データ収集が単なる表作りで終わりにくくなります。
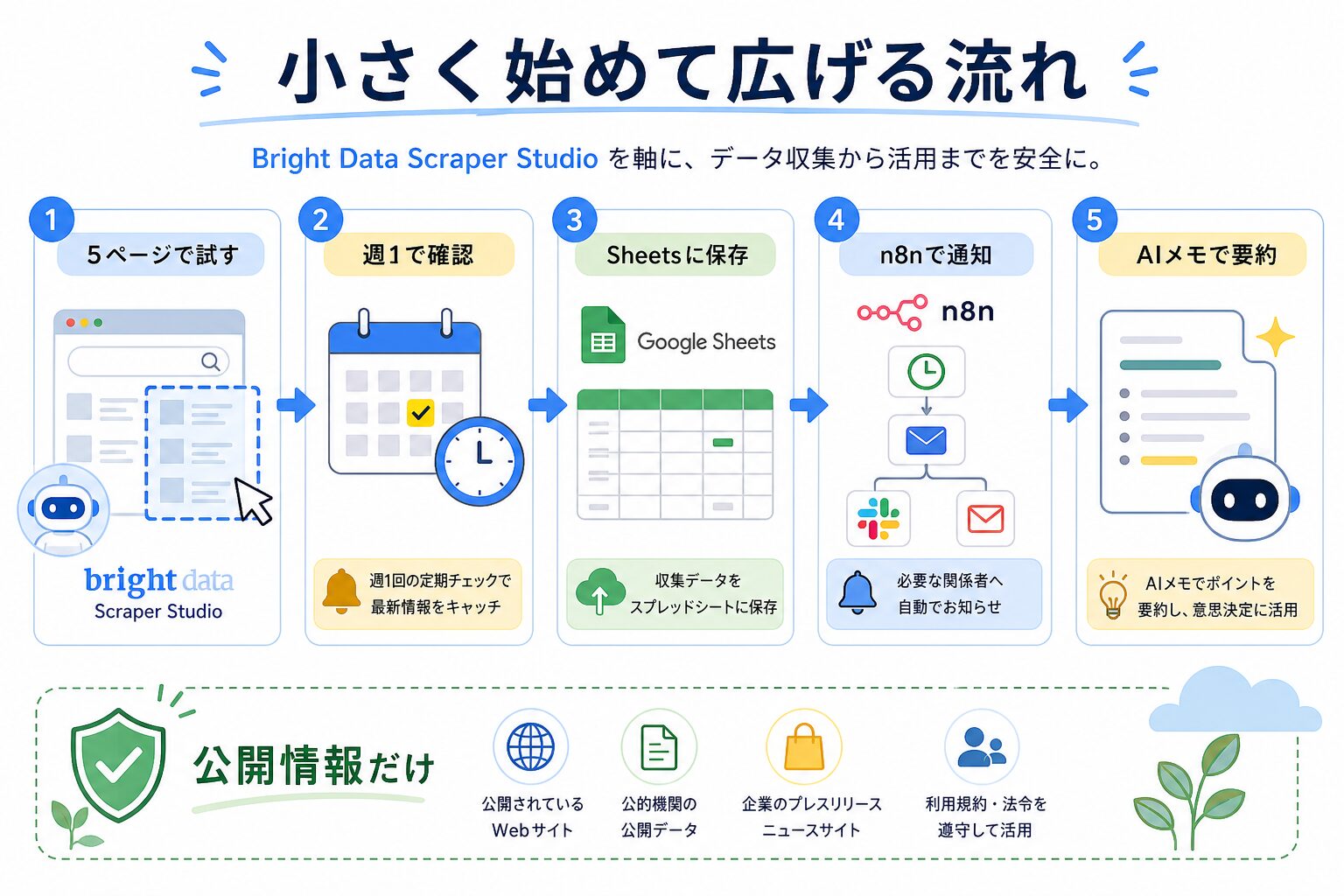
ただし、最初から全部つなぐ必要はありません。正直、最初の1回は手でCSVをダウンロードして、Google Sheetsに貼るだけでも十分です。列名が分かりやすいか、値がズレていないか、仕事で本当に見るか。そこを確かめてからn8nへ進む方が、後戻りが少ないです。
身近なたとえなら、家計簿アプリを入れる前に、まずレシートを5枚だけ見て「食費」「日用品」「交通費」に分ける感じです。分類が決まっていないのに自動化すると、後で全部直すことになります。Scraper Studioでも同じで、URL、取得日、項目名、保存先を先に固めておくと、AIや自動化に渡しやすくなります。
安全に使うための境界線
Scraper Studioは便利ですが、公開Webデータを安全に扱う前提を外すと危なくなります。対象は公開されているページに絞ります。サイト規約、robotsの考え方、プライバシー、適用される法律を確認します。少量から試し、必要以上に高い頻度でアクセスしない。ここは面倒でも外さない方がいいです。
逆に、これはやらない方がいいです。ログイン後の非公開画面を対象にすること、個人情報を不適切に集めること、スパムやアカウント悪用につながる使い方、相手サイトに迷惑な頻度でアクセスすることです。Bright DataのAcceptable Use Policyでも、違法または非準拠な使い方への厳しい姿勢が示されています。
イメージとしては、公開されているチラシを見て価格をメモするのは普通の調査です。でも、店のバックヤードに入って在庫台帳を見ようとするのは別の話です。ツールが便利になるほど、この線引きを先に決めておく必要があります。
対象は公開Webデータに絞ります。サイト規約、robotsの考え方、プライバシー、適用される法律を確認し、少量から試してください。非公開情報、個人情報の不適切な取得や保存、スパム、アカウント悪用、不正アクセスには使わないでください。
Bright Data Scraper Studioが合う人、まだ早い人
Scraper Studioが合うのは、公開ページから同じ項目を繰り返し見たい人です。EC担当者、広告運用者、メディア運営者、AIリサーチ担当者、データ整理をしたい個人事業主には検討しやすいと思います。特に「手作業では見られるけれど、毎週続けるのがしんどい」作業と相性がいいです。
反対に、月に1回だけ2ページを見るくらいなら、まだ手作業で十分かもしれません。まずはスプレッドシートに列を作り、手で5件だけ記録してみる。その表が仕事で本当に使われるなら、Scraper Studioで自動化を考える。順番としてはそのくらいで大丈夫です。
もう1つ、コードを書ける人にとってもScraper Studioは候補になります。AI Agentで叩き台を作り、IDEで細かく直す流れが取れるからです。開発者だけの道具でも、完全な初心者だけの道具でもありません。最初の入口を低くしつつ、必要なら作業台へ移れる道具、と見るのが近いです。
まとめ
Bright Data Scraper Studioは、公開Webページから必要な項目を表にするための作業場です。AI Agentを使えば、自然な文章で欲しいデータを説明し、出力項目やスクレイパー作成の入口を作れます。IDEを使えば、JavaScriptで細かい調整もできます。
初心者は、最初から大きく始めなくて大丈夫です。5ページ、5項目、週1回。商品名、価格、在庫表示、レビュー数、URL、取得日くらいから始めると、仕事で見るべき表になりやすいです。慣れてきたら、Google Sheets、n8n、BI、AIリサーチノートへ広げます。
ただし、使う範囲は公開情報に絞ります。規約や法律を確認し、少量で試し、人が最後に判断する。この順番を守ると、Scraper Studioは「難しそうなWebデータ収集」を、かなり現実的な仕事の道具として考えやすくなります。

