
この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
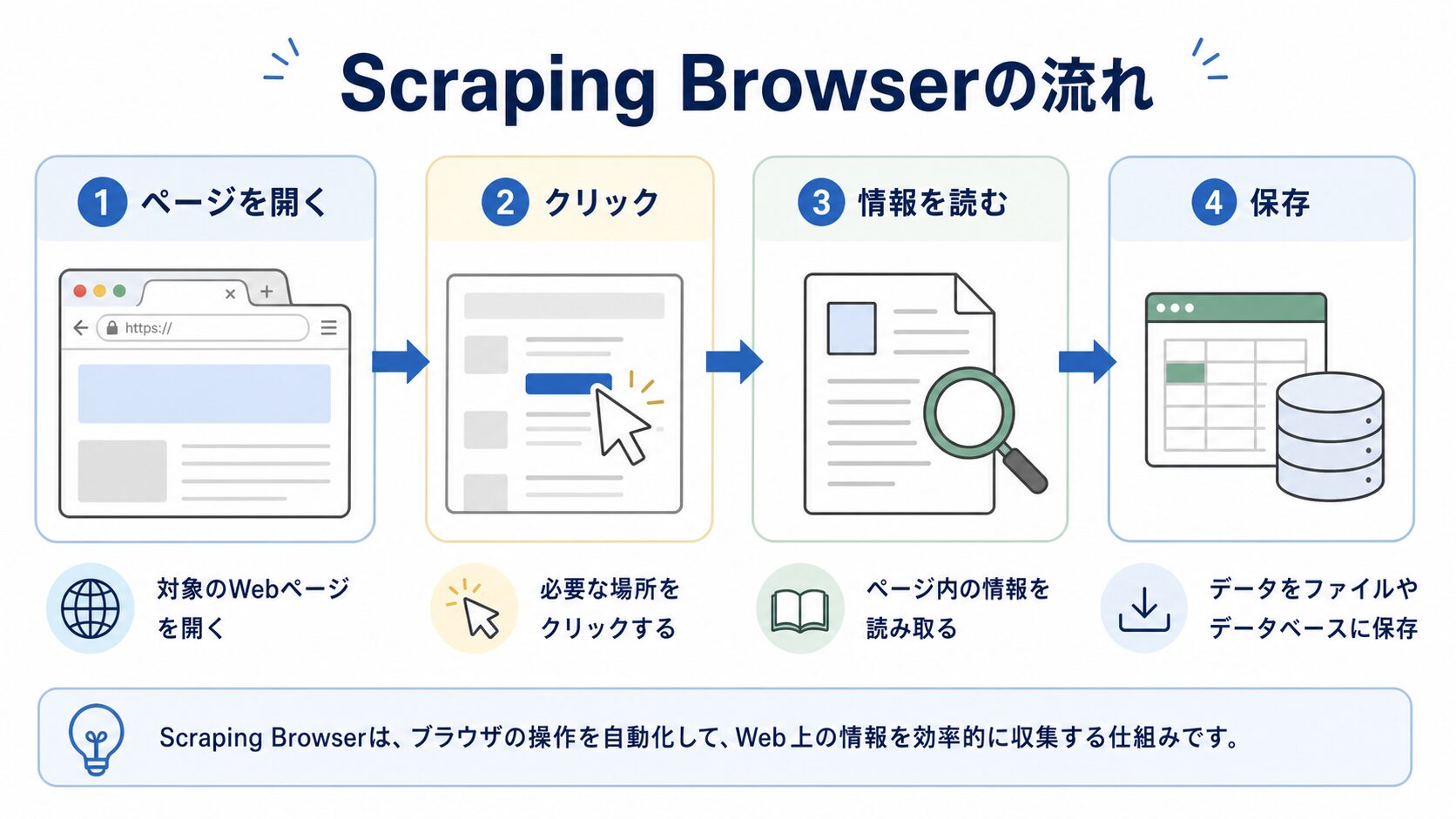
ざっくり言うと、Scraping Browserはブラウザでページを開いて操作する流れを、自動化しやすくする仕組みです。
普通のAPIで取れるページなら、それだけで十分なこともあります。ただ、ページによってはクリックした後に情報が出たり、画面の読み込みを待つ必要があったりします。
イメージとしては、人間がブラウザで「開く、待つ、クリックする、読む」と進める作業を、仕事用に整えたブラウザで行う感じです。
Scraping Browserは、動きのある公開ページを扱いたいときに使いやすい機能です。最初は「ブラウザ操作が必要なページ向け」と考えると分かりやすいです。
Scraping Browserとは?まずはざっくり理解しよう
Scraping Browserは、ブラウザを使って公開Webページにアクセスし、必要な情報を取得するためのBright Dataの機能です。
たとえば、ページを開いてすぐ全情報が見えるサイトもあれば、スクロールやクリックの後に内容が出るサイトもあります。
後者のようなページでは、ただURLを取りに行くだけでは足りないことがあります。そこでブラウザ操作に近い形が役立ちます。
どんなページに向いているのか
Scraping Browserは、動的なページに向いています。動的というのは、ページを開いた後に内容が変わったり、操作によって表示が変わったりするページのことです。
たとえば、商品一覧をスクロールすると追加表示されるページや、ボタンを押すと詳細が出るページです。
最初はここまで分かれば十分です。クリックや待機が必要なら、Scraping Browserの出番かもしれないと考えてください。

普通のスクレイピングと何が違うのか
普通のスクレイピングは、HTMLを取得して必要な情報を読む形が多いです。
イメージとしては、完成済みのチラシを受け取って、必要な行だけ読むようなものです。
一方でScraping Browserは、チラシが表示されるまでの操作も含めて扱います。実務では、ECページ、検索結果、公開ダッシュボード風のページなどで考えやすいです。
具体的な活用例
初心者の方は、まず次のような用途をイメージすると分かりやすいです。
安全に使うための注意点
ここがポイントです。Scraping Browserは便利ですが、何でも自動で集めてよいわけではありません。
逆に、これはやらない方がいいです。ログイン後の情報を取る、個人情報を集める、対象サイトに負荷をかける。こうした使い方は避けてください。
最初は少ないページで試し、対象サイトの規約や取得頻度を確認しましょう。
ブラウザで見えるからといって、何でも自動取得してよいわけではありません。公開情報の範囲とサイトのルールを確認しましょう。
Bright Dataを確認してみる
クリックや待機が必要な公開ページを扱うなら、Scraping Browserは候補になります。
EC調査、競合調査、AIリサーチの下準備に使えそうか、Bright Dataの機能を確認してみてください。
まとめ
Scraping Browserは、ブラウザ操作が必要な公開ページを扱いやすくする機能です。
単純なHTML取得で足りない場面、たとえばクリックや待機が必要なページで検討しやすいです。
ただし、公開情報とルール確認が前提です。まずは小さく試しましょう。

