

この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
GoogleスプレッドシートとBright Dataで公開Webデータを整理する入門
毎週、商品ページや検索結果を見に行って、価格や在庫、レビューの変化をメモしていると、だんだん「見る作業」より「記録する作業」が重くなってきます。数件なら手作業でも回りますが、確認先が増えると、いつ見たのか、どこが変わったのかが分かりにくくなります。
このとき入口として分かりやすいのが、Bright Dataで取得した公開WebデータをGoogleスプレッドシートに並べる考え方です。ざっくり言うと、Web上の公開情報を、あとから見返しやすい表にしておく流れです。
最初はここまで分かれば十分です。Bright Dataはデータ取得の部分を助け、Googleスプレッドシートは確認と整理の場所になります。いきなり大きな自動化を作るより、まずは小さな表で変化を見えるようにする方が、失敗が少なくなります。
この記事で分かること
- Bright DataとGoogleスプレッドシートを組み合わせる基本イメージ
- 価格、在庫、レビューなどを表で整理する実務例
- n8n、Zapier、Apps Script、AIメモへ広げる考え方
- 初心者が最初に決めておくべき列と更新ルール
- 安全に使うための境界線
まず何ができるのか
Bright DataのWeb Scraper APIは、対応する公開ページから情報を取り出し、JSONやCSVのような形で受け取れる機能です。JSONは少し難しく聞こえますが、イメージとしては「名前、価格、URL、日付」といった項目が入った整理前の伝票です。
Googleスプレッドシートは、その伝票を行と列に並べるノートのような場所です。たとえば、EC商品のURL、取得日、価格、在庫表示、キャンペーン文言を1行ずつ記録しておくと、あとから「先週と今週で何が変わったか」を見やすくなります。
ここでつまずきやすいのは、最初から完璧な自動化を作ろうとすることです。まずは5件から10件の公開ページを対象にして、手動でCSVを貼り付ける、または小さな連携だけを試すくらいで十分です。表が役に立つと分かってから、更新頻度や対象数を増やす方が安全です。
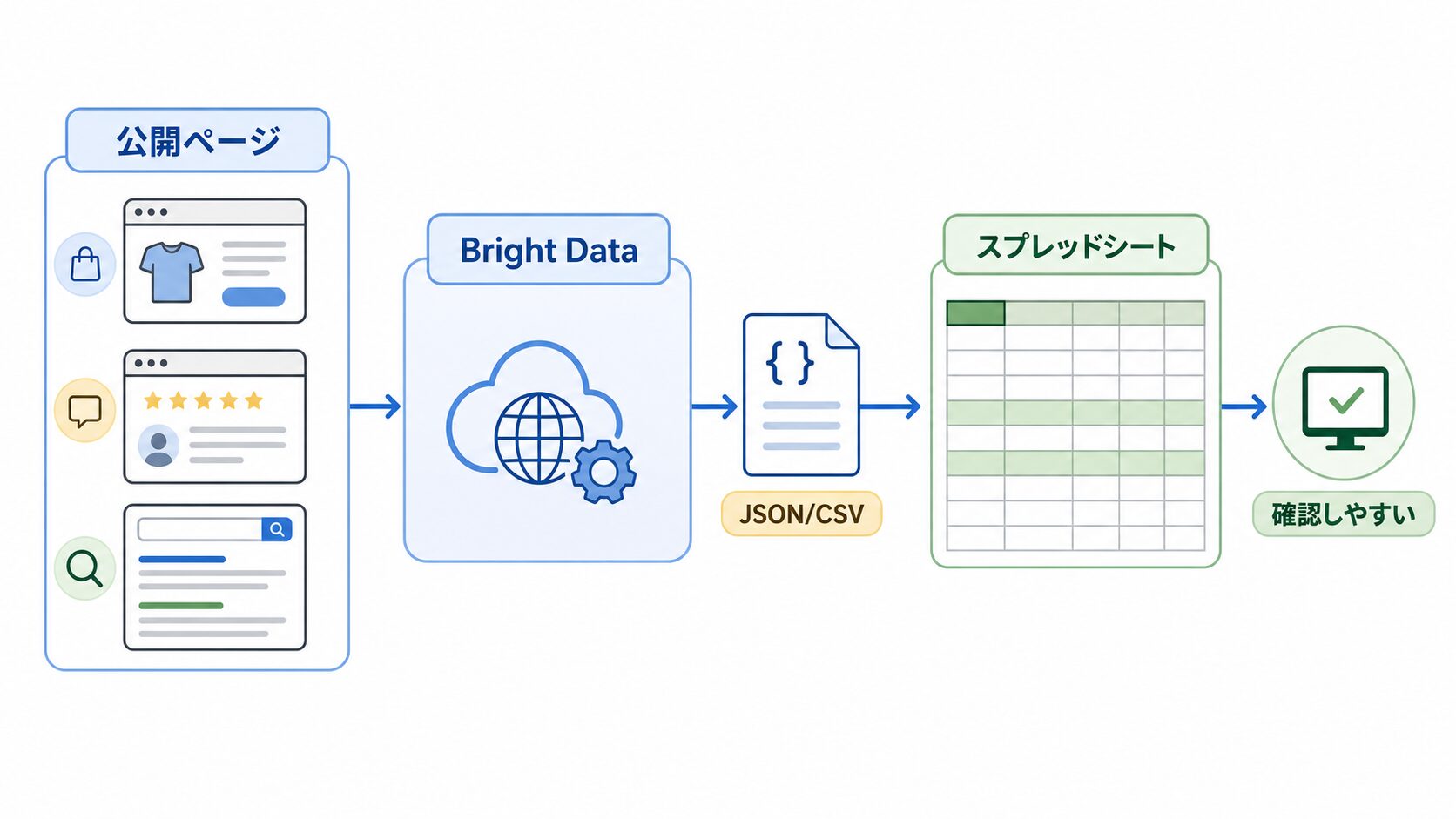
Bright Data側の役割
Bright Data側の役割は、公開Webデータを仕事で使いやすい形に近づけることです。公式ドキュメントでは、Web Scraper APIはURLを渡して構造化データを受け取る用途として説明されています。つまり、ページを人が見てメモする代わりに、必要な項目をデータとして取り出す入口になります。
たとえるなら、Webページは雑誌の切り抜きがたくさん入った箱です。Bright Dataは、その箱から「商品名」「価格」「レビュー数」のような見出しを拾って、表に入れやすい形に整える係です。Googleスプレッドシートは、その切り抜きを日付順に貼っていく台帳です。
ただし、Bright Dataを使えば何でも自由に取ってよい、という話ではありません。対象は公開情報に絞り、サイトの利用規約、robotsの案内、法律、プライバシーへの配慮を確認します。仕事で使うなら、後から説明できる集め方にしておくことが大切です。
スプレッドシート側で決める列
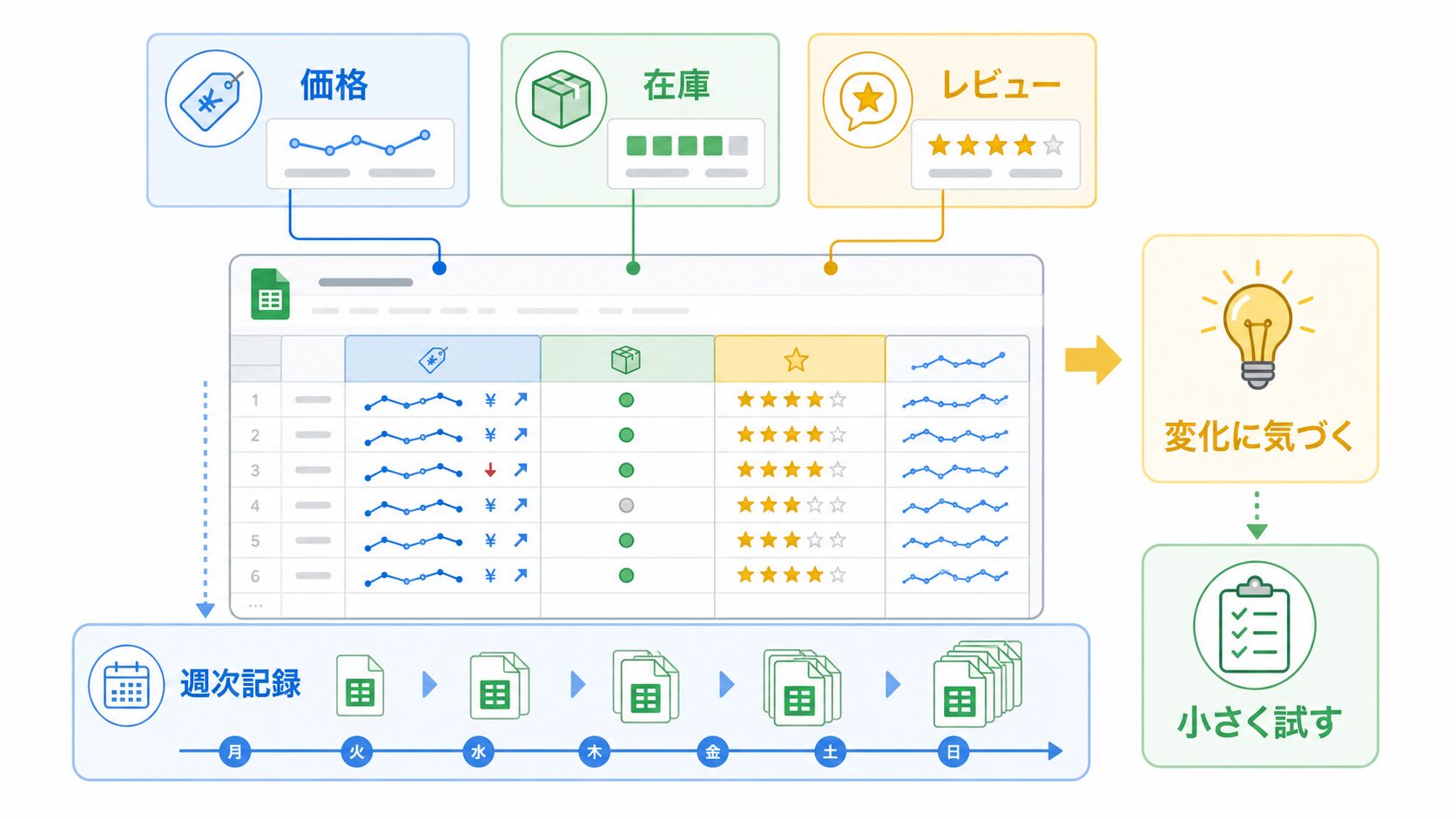
スプレッドシートで最初に作る列は、難しくしない方が続きます。たとえば、EC調査なら「取得日」「対象URL」「商品名」「価格」「在庫表示」「メモ」くらいから始めます。検索結果を見るなら「検索語」「地域」「順位」「ページタイトル」「URL」「確認日」が分かりやすいです。
イメージとしては、家計簿に近いです。家計簿も、最初から細かすぎる分類を作ると続きません。まず日付、支出先、金額、ひと言メモがあれば、あとから振り返れます。Webデータも同じで、最初は「変化に気づける最低限の列」を作るのがポイントです。
実務では、列名を固定しておくと後が楽です。毎回列が変わると、グラフやフィルター、AIへの要約依頼が使いにくくなります。最初に小さな型を作り、Bright Dataから受け取ったJSONやCSVをその型に合わせて入れると、チーム内でも共有しやすくなります。
普通の仕事ではどう使うのか
使い道の1つ目は、EC価格の確認です。競合商品の公開ページを対象にして、価格、送料表示、セール文言を週1回記録します。スプレッドシートに残しておけば、値下げが一時的なものか、数週間続いている傾向なのかを見やすくなります。注意点は、無理な頻度でアクセスしないことです。まずは少数ページ、低頻度で試します。
2つ目は、在庫や販売ステータスの観察です。たとえば「在庫あり」「売り切れ」「予約受付中」のような公開表示を記録しておくと、仕入れや記事更新の判断材料になります。これは倉庫を直接のぞくのではなく、店頭に出ている札を定期的に写真で残すイメージです。見える範囲の公開表示だけを扱う、という線引きが大事です。
3つ目は、レビューや口コミの整理です。公開レビューの件数、評価、よく出る言葉を表にしておくと、商品改善や記事作成の下調べに使えます。ただし、個人を特定する目的で集めたり、必要以上に個人に近い情報を扱ったりしないようにします。仕事で見るべきなのは、個人そのものではなく、商品やサービスへの傾向です。
慣れてきたらどこまで広げられるのか
基本の表が動き始めたら、次は自動化に広げられます。たとえば、n8nやZapierでBright Dataの結果を受け取り、Googleスプレッドシートに行を追加する流れを作れます。コードが得意なら、Google Apps ScriptでCSVを読み込む形でも構いません。
この段階の考え方は、手作業のバケツリレーを少しずつベルトコンベアに変えるイメージです。最初は人が結果を確認して貼り付ける。次に、決まった形の結果だけ自動で行追加する。さらに慣れたら、価格が一定以上変わった行に色を付けたり、前回との差分だけを別シートにまとめたりできます。
AIリサーチにも広げられます。スプレッドシートにたまった公開データを、AI用の調査メモとして渡し、「今週目立った変化」「レビューで増えている不満」「競合が強調し始めた訴求」を要約してもらう流れです。ここでも、AIに丸投げせず、元データのURL、取得日、見た範囲を残しておくと確認しやすくなります。
逆に何をやらない方がいいのか
逆に、これはやらない方がいいです。ログイン後の画面、会員だけに見える情報、個人に深く関わる情報、サイトのルールに反する集め方を前提にした運用です。Bright Dataやスプレッドシートは便利ですが、便利な道具ほど、使う範囲を先に決めておく必要があります。
たとえるなら、スプレッドシートは共有しやすい大きなホワイトボードです。便利な反面、不要な情報まで書くと、関係ない人にも見えてしまいます。だから、集める前に「この列は本当に必要か」「社内で共有してよい内容か」「公開情報だけか」を確認します。
最初の小さな始め方
初心者におすすめなのは、1テーマ、5URL、週1回です。たとえば「競合商品の価格だけを見る」「自社名の検索結果だけを見る」「レビュー件数の増減だけを見る」のように、目的を1つに絞ります。表の列も6列前後にして、まずは見返せる状態を作ります。
ここがポイントです。自動化そのものより、表の型が先です。型がないまま自動化すると、データは増えているのに判断に使えない、という状態になりやすいです。
Bright Dataが向いている人・向いていない人
Bright Dataが向いているのは、公開Webデータを継続して見たい人です。EC運営者、SEO担当者、メディア運営者、マーケター、AIリサーチの材料を整理したい人には相性があります。スプレッドシートに並べると、専門ツールを作る前の試作としても使いやすいです。
一方で、たまに1ページだけ見る人には大きすぎる場合があります。その場合は、まず手作業で十分です。料理で言えば、毎日同じ下ごしらえをするなら道具をそろえる価値がありますが、1回だけなら包丁とまな板で足ります。
また、社内でデータの扱い方を決められない段階でも急がない方がいいです。誰が見るのか、どのくらい保存するのか、どの情報は入れないのかを決めてから始めると、あとで困りにくくなります。
まとめ
GoogleスプレッドシートとBright Dataの組み合わせは、公開Webデータをいきなり大きなシステムにするのではなく、まず表で見えるようにする入口です。価格、在庫、レビュー、検索結果のような情報を、取得日とURLつきで残すだけでも、仕事の判断材料として使いやすくなります。
最初は小さく始めてください。5URL、週1回、最低限の列で十分です。そこから、n8nやZapierで行追加を自動化したり、AIリサーチ用のメモに広げたりできます。つまり、Bright Dataは取得の入口、Googleスプレッドシートは確認の台帳として考えると、初心者でも無理なく進めやすくなります。

