

この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
Web UnlockerとBrowser APIの違いを初心者向けに比較
公開ページを集めたいだけなのに、「Web Unlockerでいいのか、Browser APIまで必要なのか」で手が止まることがあります。名前だけ見るとどちらも似ていますし、どちらもWebデータ取得の話に出てきます。
結論から言うと、ページを取得して中身を読むのが中心ならWeb Unlocker、クリック・スクロール・待機などブラウザ操作が必要ならBrowser APIと考えると分かりやすいです。たとえばEC担当者が競合商品の価格や在庫表示を週1回確認したいなら、まずWeb Unlocker側から考える。検索条件を入れたり、ボタンを押したり、表示があとから変わるページを扱うならBrowser APIを検討する、という順番です。
この記事では、どのBright Data機能を選ぶか迷っている初心者向けに、Web UnlockerとBrowser APIの違いを仕事の場面から整理します。最初はここまで分かれば十分です。万能な方を探すより、「今回の作業は取得なのか、操作なのか」を先に分ける方が失敗しにくいです。
– Web UnlockerとBrowser APIの基本的な違い
– 初心者が先に見るべき選び方
– EC、SEO、マーケティングでの安全な使い分け
– Google Sheets、n8n、AIメモへ広げる流れ
– やらない方がいい使い方と安全な境界線
まずは「取得」か「操作」かで分ける
Web Unlockerは、公開Webページを取得するときのつまずきを減らすための機能です。公式ドキュメントでは、対象URLを1回のAPIリクエストで送り、HTMLやJSONのレスポンスを受け取る考え方が説明されています。イメージとしては、閉まりやすい受付窓口で、入館手続きだけを専門スタッフに任せる感じです。こちらは、その後に必要な項目を読むことに集中できます。
一方のBrowser APIは、ブラウザを動かす必要がある作業向けです。Bright Data側の管理されたクラウドブラウザに、Puppeteer、Playwright、Seleniumのような自動操作ツールで接続し、クリック、スクロール、フォーム入力、JavaScriptで後から出る内容の読み込みなどを扱います。こちらは、受付を通るだけでなく、建物の中を歩いて、棚を開けたり、次の画面へ進んだりする仕事に近いです。
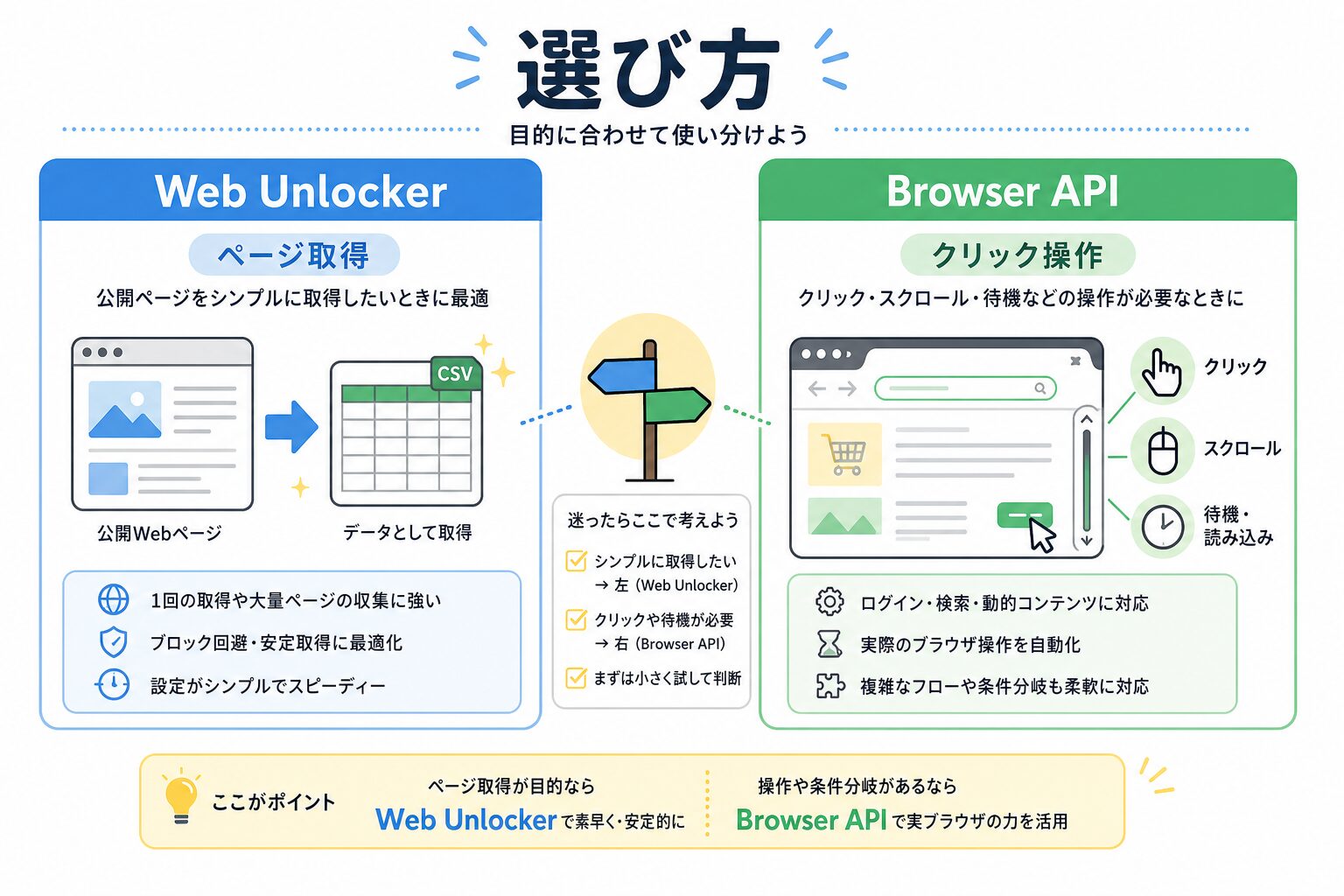
ここでつまずきやすいのは、「高機能そうだからBrowser APIを選ぶ」と考えてしまうことです。たしかにBrowser APIはできることが広いです。ただ、毎週5商品の価格・在庫表示・キャンペーン文言を取るだけなら、ブラウザ操作まで必要ないケースもあります。台所で包丁だけで済む作業に、いきなり業務用ミキサーを出すようなものです。
Web Unlockerが向いている仕事
Web Unlockerが向いているのは、公開ページを取り、HTMLやJSONとして受け取り、そこから必要な情報を読む仕事です。たとえばEC担当者が、競合5商品の公開商品ページから、価格、在庫表示、キャンペーン文言、レビュー数、取得日、元URLを週1回Google Sheetsに残すような使い方です。
公式ドキュメントでは、Web Unlockerはプロキシ、ヘッダー、フィンガープリント、CAPTCHA対応、リトライのような取得まわりの複雑さをまとめて扱う機能として説明されています。難しく聞こえますが、初心者向けに言えば「ページを取りに行くところで毎回細かく詰まらないようにする係」です。倉庫で商品を探す前に、まず入館証の手続きを任せるようなイメージです。
普通の仕事では、価格調査やニュース収集、競合ページの更新確認に使いやすいです。マーケティング担当者なら、競合の公開キャンペーンページを週1回見て、見出し、訴求文、キャンペーン期限、URLを表に残します。SEO担当者なら、公開記事ページのタイトル、更新日、見出しの変化を確認し、記事リライトの優先度を決める材料にします。
ただし、Web Unlockerはブラウザ自動操作のための機能ではありません。Bright Dataの公式ドキュメントでも、PuppeteerやPlaywrightなどの第三者ブラウザツールで使う用途ではなく、ブラウザ操作が必要ならBrowser APIを使う方向が案内されています。ここは少し迷いやすいです。URLを渡してページを取得するだけならWeb Unlocker。画面の中で人のように動く必要があるなら、Browser API側です。
Browser APIが向いている仕事
Browser APIが向いているのは、ページを開いたあとに操作が必要な仕事です。たとえば、JavaScriptで商品一覧があとから表示される、スクロールしないと次の商品が出ない、地域や条件を選ぶと結果が変わる、ボタンを押して詳細を開く。こういう場合は、単にURLを取るだけでは足りないことがあります。
公式ドキュメントでは、Browser APIは管理されたクラウドブラウザでスクレイピング用の処理を動かし、Puppeteer、Playwright、Seleniumと連携できると説明されています。たとえるなら、Web Unlockerが「資料を取り寄せる係」だとすると、Browser APIは「実際に画面を操作して必要な棚まで見に行く係」です。
実務例で見ると分かりやすいです。広告運用者が、公開されている広告ライブラリや検索結果周辺の表示を確認するとします。条件選択、タブ切り替え、スクロール、読み込み待ちがあるならBrowser APIの方が考えやすいです。EC担当者が、商品一覧で「もっと見る」を押してから表示される公開商品を確認したい場合も同じです。
逆に、これはやらない方がいいです。Browser APIを「なんでも大量に回す道具」として使うことです。ブラウザは便利ですが、処理は重くなりやすく、設計も少し複雑になります。最初から全部をブラウザ操作にすると、費用、時間、確認ポイントが増えます。まず少数ページで、どの操作が本当に必要なのかを確認した方がいいです。
実務での安全な使い分け例
1つ目はEC価格・在庫チェックです。EC担当者が、競合5商品の公開ページを毎週月曜に確認し、価格、在庫表示、キャンペーン文言、レビュー数、取得日、URLをGoogle Sheetsに残します。ページを開けば情報が見えているならWeb Unlockerから考えます。もし「もっと見る」を押さないと商品が出ない、スクロールで追加表示される、条件選択で価格が変わるならBrowser APIを検討します。判断に使うときは、値下げだけでなく、送料表示や商品ページの訴求も一緒に見ます。
2つ目はSEOやメディア運営の調査です。メディア運営者が、競合記事の公開ページからタイトル、更新日、見出し、内部リンクの変化を月1回確認します。単純なページ取得ならWeb Unlockerで十分なことがあります。ページ内のタブを切り替えないと情報が出ない、JavaScriptで本文が後から出る、といった場合はBrowser APIの出番です。ここで大事なのは、取得した見出しだけで記事を真似しないことです。読者の疑問、公式情報、元URLを見て、自分の記事の不足を確認します。
3つ目はマーケティングや広告調査です。広告運用者が、競合の公開LPやキャンペーンページを週1回見て、ファーストビューの見出し、価格訴求、キャンペーン期限、CTA文言を記録します。固定ページならWeb Unlockerで取得し、表に残す形が分かりやすいです。地域選択やステップ表示があるLPならBrowser APIで操作が必要になるかもしれません。結果はGoogle Sheetsや週次レポートへ入れ、次の広告文やLP改善の材料にします。
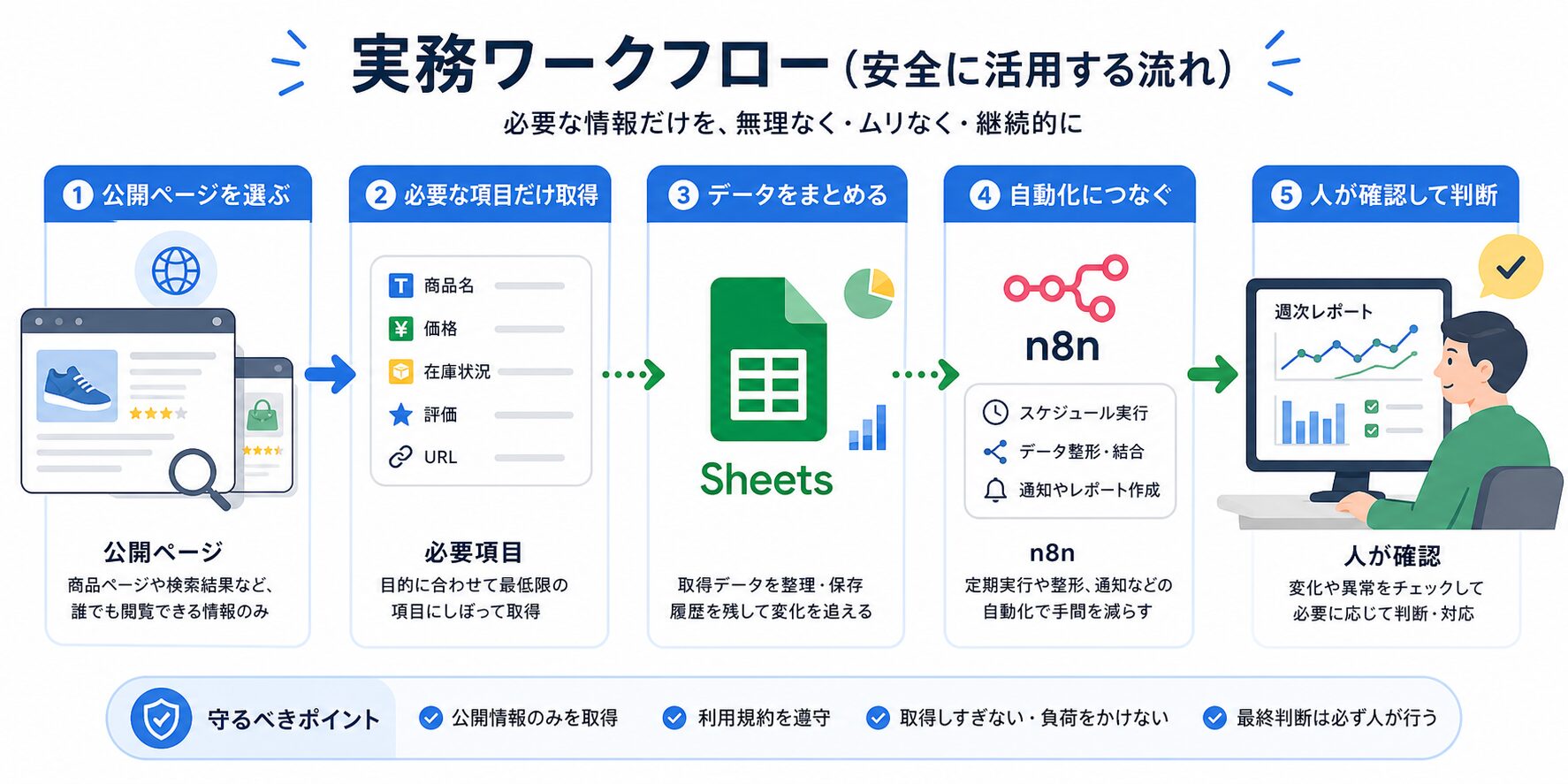
4つ目はAIリサーチメモへの応用です。公開ページのタイトル、URL、更新日、重要な見出しだけを集め、AIには「今週変わった点」や「確認すべきURL」をまとめてもらいます。ここはn8nと相性がいいです。たとえば、Web UnlockerまたはBrowser APIで少数の公開ページを処理し、n8nでGoogle Sheetsへ追記し、AIメモには差分だけ渡します。AIに判断を丸投げするのではなく、最後に人が元URLを見て確認する。ここがポイントです。
初心者は小さく試してから広げる
最初に決めることは、機能名ではなく作業の形です。対象ページは5件でいいです。見る項目も、価格、在庫表示、見出し、更新日、URL、取得日くらいで十分です。毎週同じ条件で取って、表に残し、人が確認する。これだけで「Web Unlockerで足りるのか、Browser APIが必要なのか」がかなり見えます。
イメージとしては、引っ越し前に全部の家具を買うのではなく、まず机と椅子だけ置いて生活してみる感じです。実際に使うと、「ここはスクロールが必要だった」「このページは取得だけで済んだ」「この項目は判断に使われなかった」と分かります。
正直、最初から完璧な自動化を作る必要はありません。1回だけ動いた仕組みより、毎週見返せる小さな表の方が役に立つことがあります。特に初心者は、取れるデータの量より「そのデータで何を決めるのか」を先に書いておく方がいいです。
安全に使うための境界線
Bright DataのAcceptable Use Policyでも、違法・不正・悪用目的の利用は禁止されています。記事としてもここははっきり分けます。対象は公開Webデータに限り、サイト規約、robotsの考え方、プライバシー、適用される法律を確認します。非公開情報、ログイン後の情報、個人情報の不適切な収集、スパム、アカウント悪用、不正アクセスには使いません。
ここで大事なのは、「できるか」と「やってよいか」を分けることです。道具としてページ取得やブラウザ操作ができても、対象サイトのルールや法律に合わない使い方は避けるべきです。包丁が便利でも、使い方を間違えると危ないのと同じです。
また、頻度を上げすぎないことも大切です。初心者は、毎分大量に取得するより、週1回や1日1回の小さなチェックから始めます。重要な判断は、表だけで終わらせず、元URLと取得日を見て人が確認します。AIメモを使う場合も、AIの要約だけを根拠にしない方が安全です。
ログイン後の非公開情報、個人情報の不適切な収集、スパム、アカウント作成の自動化、不正アクセス、サイトへ過度な負荷をかける取得には使わないでください。公開情報を、必要な範囲で、少量から試すのが前提です。
どちらを選ぶか迷ったときの考え方
迷ったら、まず作業を1行で書いてみます。「競合5商品の価格と在庫表示を週1回Sheetsに残す」。この場合は取得が中心なので、Web Unlockerから考えます。「条件を選び、ボタンを押し、スクロールして出てきた公開商品を確認する」。この場合は操作が中心なので、Browser APIを検討します。
Web Unlockerは、公開ページの取得をシンプルにしたい人に向いています。Browser APIは、実ブラウザでの操作が必要な人に向いています。どちらもBright DataのWebデータ取得の選択肢ですが、役割は同じではありません。ドライバーと配送トラックくらい違います。荷物を受け取るだけなら配送で済む。現地で棚を動かすなら人が行く必要がある。そんな分け方です。
まとめると、初心者は次の順番で考えると扱いやすいです。まず公開ページだけを対象にする。次に、取得したい項目を5つ以内に絞る。ページ取得だけで済むならWeb Unlocker。クリック、スクロール、待機、フォーム操作が必要ならBrowser API。慣れてきたら、Google Sheets、n8n、BI、AIリサーチメモへ広げる。最後の判断は人が確認する。
最初は、機能を完璧に覚えるより、自分の作業を「取得」と「操作」に分けるだけで十分です。そこが分かると、Bright Dataの中でどの入口を選べばいいかがかなり見えやすくなります。

