この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
AIで調べものをするとき、意外と時間を使うのは「AIに何を渡すか」を整える部分です。検索して、ページを開いて、メモして、表に直してからAIに要約してもらう。この前処理が重いと、せっかくのAIリサーチも途中で止まりやすくなります。
結論から言うと、Bright Data Datasetsは、AIに渡す調査材料を最初から整理しやすい形で用意するための入口です。公開Webデータを、商品、企業、不動産、求人、レビューなどのテーマごとに扱いやすいデータセットとして見る考え方ですね。
たとえば、競合商品のレビュー傾向をAIに読ませたいとします。ページを一つずつ開いてコピペするより、項目がそろったデータを用意してから「不満点を分類して」と頼む方が、調査のスタート地点がかなり安定します。
Bright Data DatasetsをAIリサーチに使うなら、最初は「公開情報をAIに渡しやすい材料へ整えるもの」と考えると分かりやすいです。いきなり大規模な自動化を目指すより、少量のデータで仮説メモを作るところから始めるのが安全です。
この記事でわかること
この記事では、Bright Data Datasetsを「AIに調査材料を渡すためのデータ置き場」として整理します。イメージとしては、散らかった資料の山をAIに丸投げするのではなく、見出し付きのファイルに分けてから渡す感じです。
- Bright Data Datasetsの基本イメージ
- AIリサーチでデータセットが役立つ理由
- 市場調査、競合比較、レビュー分析での使い方
- Googleスプレッドシート、BI、AIノートへ広げる考え方
- 安全に使うための境界線
Bright Data Datasetsとは?まずはざっくり理解しよう
Datasetsは、公開Web上の情報をテーマ別に整理したデータのまとまりです。Bright Dataの公式ドキュメントでは、Dataset Marketplaceは120以上の分野からデータセットを探し、項目をカスタマイズし、希望する形式で受け取れる場所として説明されています。
難しく聞こえるかもしれませんが、身近な例で言うと「図書館の棚」に近いです。Web全体から本を探し回るのではなく、商品情報の棚、企業情報の棚、不動産情報の棚、レビュー情報の棚のように、最初から分類された場所を見に行くイメージです。
AIリサーチでは、この分類がかなり大事です。AIは文章を読んで要約したり、傾向を分けたりするのが得意ですが、材料がバラバラだと答えもぼやけます。商品名、価格、評価、日付、URLのような列がそろっていると、「価格帯ごとの傾向を見て」「低評価レビューだけ分類して」のように頼みやすくなります。
ここでつまずきやすいのは、「データセットを買えば答えまで出る」と考えてしまうことです。Datasetsは材料です。料理で言えば、切って袋詰めされた野菜に近いです。調理、味付け、食べてよいかの確認は、こちら側で考える必要があります。
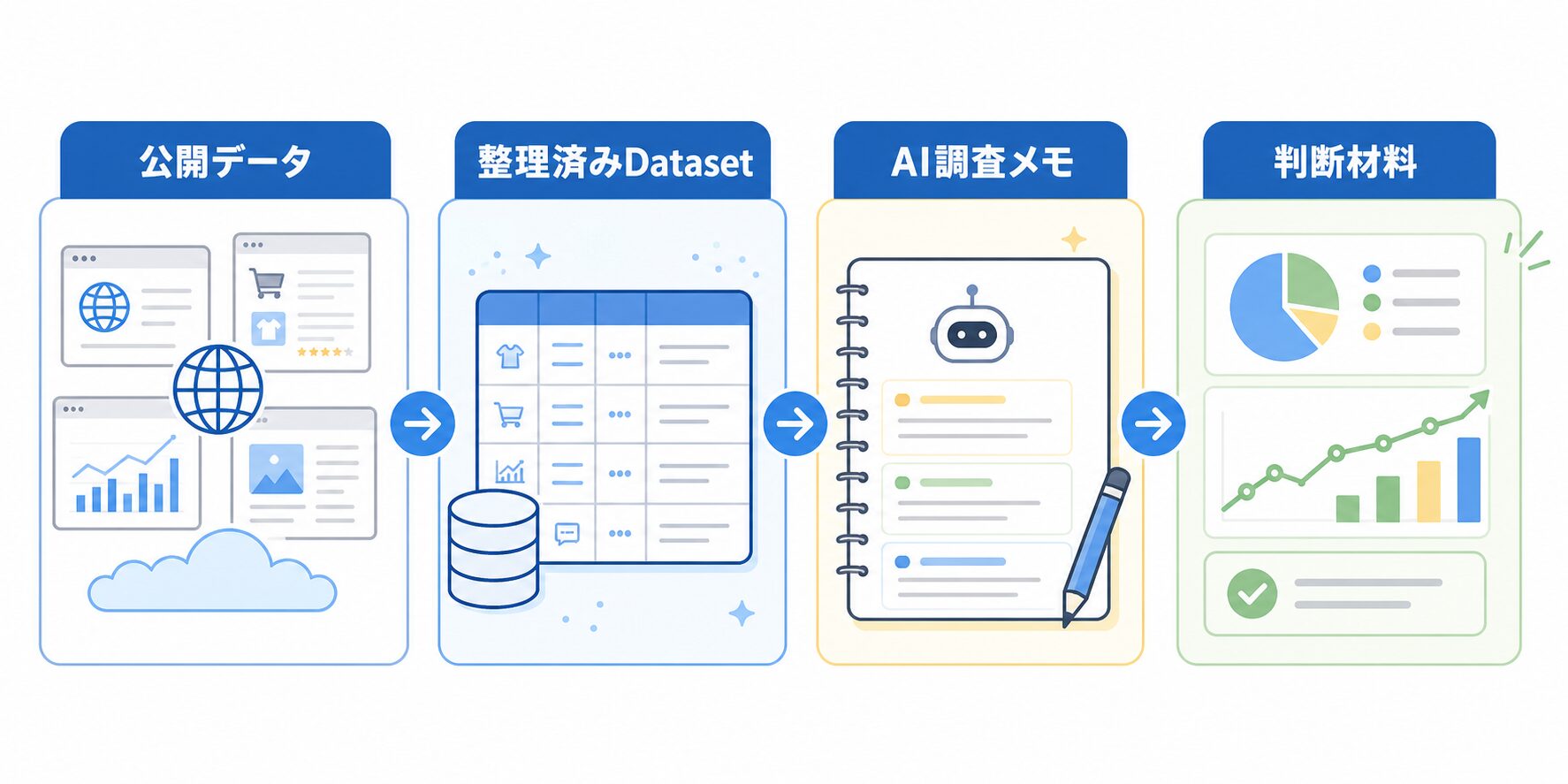
なぜAIリサーチでBright Data Datasetsが役立つのか
AIに調査を任せるとき、初心者が最初に困るのは「何を入力すればよいか」です。検索結果のURLを何本か渡すだけでも調査はできますが、比較したい項目がそろっていないと、AIの出力も感想文のようになりやすいです。
Bright Data Datasetsは、商品、企業、求人、不動産、SNS、レビューなど、仕事で見たい公開情報を構造化された形で扱いやすくします。構造化とは、表の列のように項目が分かれていることです。たとえば、商品データなら商品名、価格、評価、レビュー数、カテゴリ、URLのように分かれている状態ですね。
イメージとしては、会議前に資料をホチキス留めして配るか、机の上に紙を散らばらせるかの違いです。AIは散らばった紙も読めますが、そろった資料の方が比較や分類をしやすくなります。
公式情報では、Dataset Marketplaceはサンプル確認、フィールドの確認、フィルター、更新、購入、配信先の選択などを扱えるとされています。配信形式もJSON、CSV、XLSX、Parquetなどが用意され、API、Webhook、クラウドストレージ、メールなどの受け取り方があります。つまり、AIツールへ直接渡す前に、スプレッドシートやデータ基盤で一度整える流れを作りやすいわけです。
Datasetsは「AIが勝手に正解を出す機能」ではありません。AIに渡す前の材料をそろえるための入口です。判断は、元データの範囲、更新日、欠けている項目、利用目的を見ながら行います。
まず何ができるのか
初心者が最初にやるなら、いきなり自動化ではなく、少量のサンプルを見て「AIに読ませると何が分かるか」を確認するのが現実的です。新しい文房具を買ったとき、まず1ページだけ試し書きするのと同じです。
たとえば、EC商品のデータセットを見るなら、最初は1カテゴリだけに絞ります。商品名、価格、評価、レビュー数、説明文の列を確認し、AIに「高価格帯の商品に多い表現をまとめて」「レビュー数が多い商品に共通する特徴を出して」と頼みます。
企業情報なら、業種、地域、従業員規模、説明文、URLなどを見ます。AIに「この業界でよく出る課題ワードを分類して」と頼めば、営業リストを作る前の市場メモとして使えます。求人情報なら、職種、勤務地、給与レンジ、必要スキルを見て、採用市場の傾向をざっくり把握できます。
最初はここまで分かれば十分です。大事なのは、AIに丸投げする前に「どの列を見れば仕事の判断に近づくか」を決めることです。列が多すぎる場合は、商品名、カテゴリ、価格、評価、説明文、URLのように、まず5から6項目だけ残して試すと扱いやすくなります。
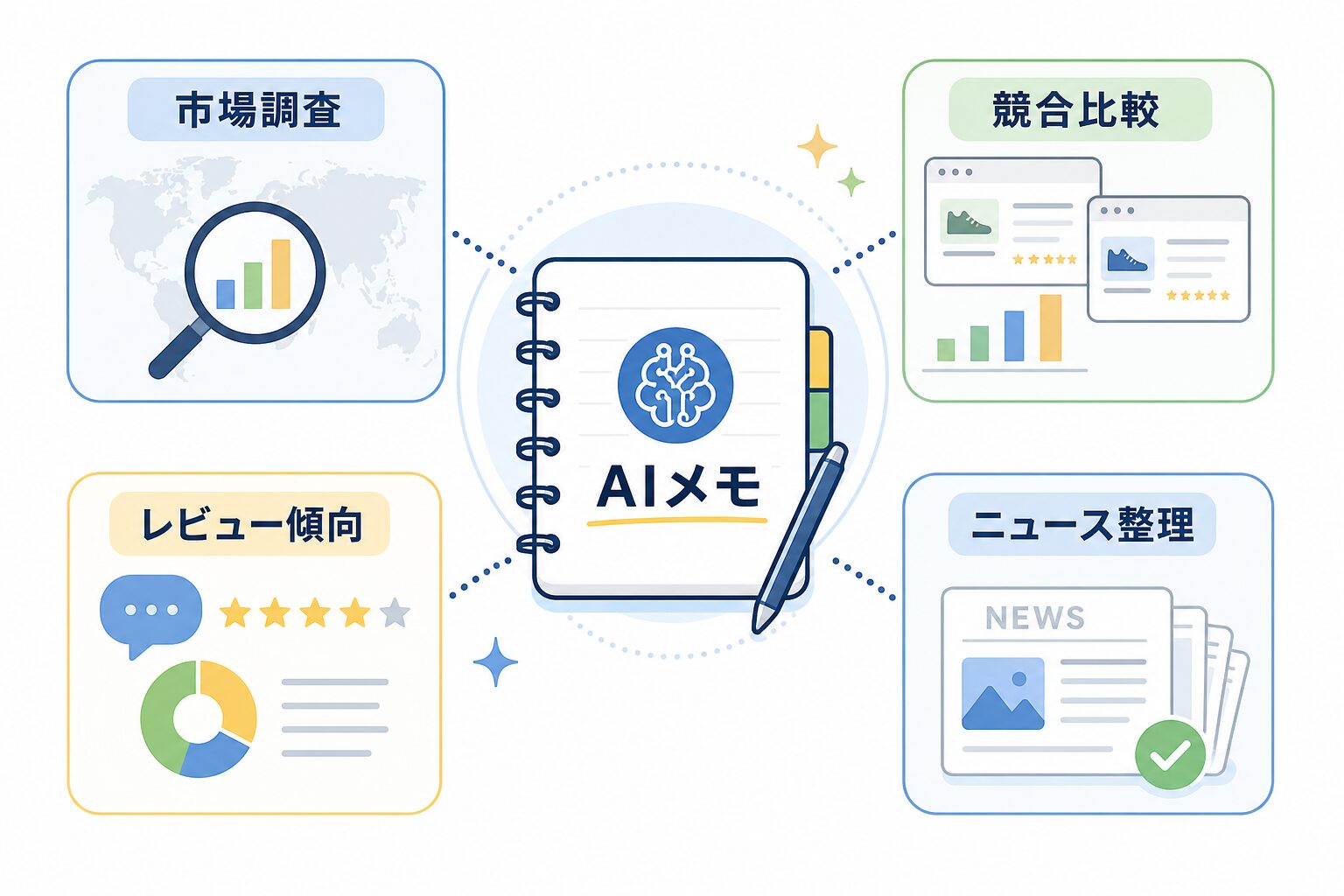
普通の仕事ではどう使うのか
1つ目は、市場調査です。新しいジャンルの記事や商品を扱う前に、公開されている商品情報、価格帯、カテゴリ、説明文を見ます。たとえば、ガジェット系ブログなら、同じカテゴリの商品名や価格帯をAIに読ませて「初心者向け」「上級者向け」「価格重視」のように分類できます。注意点は、AIの分類をそのまま市場の答えにしないことです。元データの範囲と更新日を見て、あくまで仮説として扱います。
2つ目は、競合比較です。競合商品の価格、評価、レビュー数、説明文をそろえて見ると、自社や自分のブログ記事で説明すべき差が見えやすくなります。スーパーの棚を見て、同じカテゴリの商品がどんな価格帯で並んでいるか確認する感覚です。ここでは、競合を攻撃するためではなく、自分の説明不足や見せ方の改善に使います。
3つ目は、レビュー傾向の整理です。公開レビューをAIに読ませると、「配送」「サイズ」「耐久性」「サポート」のような不満や評価ポイントを分類しやすくなります。EC運営者なら商品改善のヒントに、ブログ運営者なら比較記事で触れるべき注意点にできます。ただし、個人を特定できる情報を集めたり、レビュー投稿を操作したりする使い方はしません。
4つ目は、ニュースや業界動向の整理です。業界ニュースや企業情報のデータをAIリサーチメモに渡し、「今月増えた話題」「よく出るキーワード」「新しく名前が出てきた企業」をまとめます。毎朝すべての記事を読む代わりに、新聞の切り抜きを分類しておく感じです。最終的に記事を書くときは、必ず元URLや一次情報を確認します。
慣れてきたらどこまで広げられるのか
基本の確認ができたら、次はAIリサーチを「毎回の単発作業」から「見返せる流れ」に変えます。イメージとしては、調べもののメモを毎回付箋に書く段階から、ノートや表に残していく段階へ進む感じです。
一番始めやすいのは、Googleスプレッドシートに入れる方法です。データセットから必要な列だけを取り出し、日付、カテゴリ、価格、評価、AIメモ、確認URLのように並べます。AIには「前回と比べて増えた表現」「価格帯ごとの違い」「レビューで増えた不満」を聞きます。
少し慣れたら、n8nで定期的にファイルを取得し、スプレッドシートやNotion、AIリサーチノートへ送る流れも考えられます。さらにBIへつなげるなら、カテゴリ別の価格中央値、レビュー件数の推移、企業数の変化などをダッシュボードで見られます。
AI活用の応用では、RAGやナレッジベースの材料として使う考え方もあります。RAGは、AIが回答するときに外部資料を参照する仕組みです。たとえば、自社内の調査メモに公開データから作った要約を入れておき、「今月の競合トレンドを説明して」と聞く流れです。ただし、データの出所、利用条件、更新日を一緒に管理しないと、古い情報をもっともらしく答えてしまいます。
ここがポイントです。応用の前に、まずは「少量のデータでAIの出力が仕事メモとして使えるか」を見ます。出力がふわっとするなら、データ量を増やす前に、列の選び方や質問の仕方を直した方が早いです。
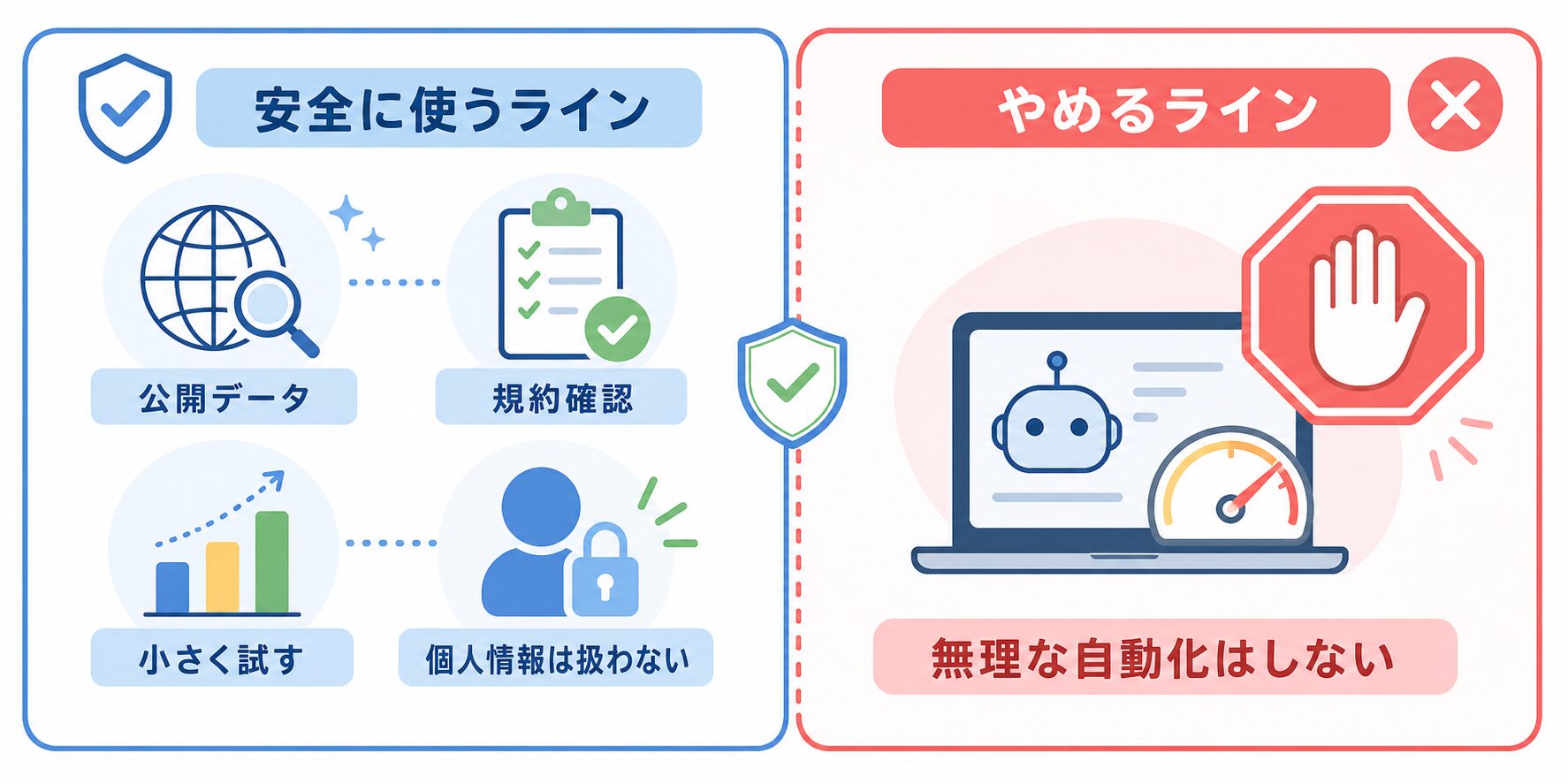
逆に、これはやらない方がいいです
Bright Data Datasetsは、公開Webデータを仕事の判断材料として扱うためのものです。非公開情報を取ろうとする、個人情報を集める、スパムやアカウント悪用に使う、といった目的には使わないでください。地図を見て街の様子を理解する道具であって、閉まっている扉を開ける道具ではありません。
また、AIに渡すときも注意が必要です。データセットに含まれる情報が公開情報でも、プライバシーや利用規約、地域ごとの法律に関わる場合があります。特に個人に関する情報、SNS、レビュー、求人、企業担当者情報のような領域では、扱う項目を絞り、必要以上に細かく追いかけない方が安全です。
もう一つ大事なのは、AIの出力をそのまま事実として扱わないことです。AIは整理や要約には便利ですが、元データの偏りや古さまでは自動で全部直してくれません。記事、広告、営業資料、意思決定に使う前に、代表的な元データと公式情報を確認します。
Bright Data Datasetsが向いている人、向いていない人
Bright Data Datasetsが向いているのは、AIリサーチの前処理に時間がかかっている人です。たとえば、ECの価格帯を見たい人、商品レビューを分類したい人、競合企業の動きを定点観測したい人、業界ニュースをAIメモにまとめたい人には相性がよいです。
逆に、1回だけ数ページを見る人には、手作業や普通の検索で十分な場合もあります。Datasetsは、同じテーマを何度も見る、項目をそろえて比較する、AIやBIへ渡す、といった場面で価値が出やすいです。小さなメモで済む調査に、いきなり大きな棚を用意する必要はありません。
また、APIやクラウド配信まで使うなら、多少の設計が必要です。どのデータを、どの形式で、どこに保存し、誰が確認するのかを決めてから始める方が続きます。最初はCSVやスプレッドシートで試し、必要になってからAPIやWebhookへ広げるくらいで十分です。
まとめ
Bright Data Datasetsは、AIリサーチの材料を整えやすくするための入口です。公開Webデータをテーマごとに見つけ、サンプルや項目を確認し、CSV、JSON、XLSX、Parquetなどの形式で受け取れるため、AIメモ、スプレッドシート、BI、RAGの材料にしやすくなります。
まずは、目的を一つに絞り、少量のデータで試してください。市場調査なら価格帯やカテゴリ、競合比較なら商品名や評価、レビュー分析なら不満や評価ポイント、ニュース整理なら増えている話題を見ます。慣れてきたら、Googleスプレッドシート、n8n、BI、AIリサーチノートへ広げられます。
ただし、公開データだけを扱い、規約や法律、プライバシーを確認し、AIの出力を元データで見直すことが前提です。つまり、Datasetsは答えそのものではなく、AI調査を落ち着いて始めるための整理棚として使うのが現実的です。